Migrating WordPress to GatsbyJS - Search Engine Optimization


Table of Contents
- Migrating WordPress to GatsbyJS - Introduction
- Migrating WordPress to GatsbyJS - Blog Posts
- Migrating WordPress to GatsbyJS - Architecture & CI/CD
- Migrating WordPress to GatsbyJS - Search Engine Optimization
Have you ever wondered why certain sites appear at the top of results when you Google them? It goes without saying that the higher you are on the results page, the more likely you are to get traffic. This ranking is heavily based on Search Engine Optimization (SEO), and it's a very important part of being successful in an online space.
In this post I will explain why SEO is super important, and how you can handle moving your WordPress site to GatsbyJS without destroying search rankings.
Search Ranking
Before we begin let's take a look at an example of my own search engine rankings to better understand how they work. Below is an example DevOpStar landing as the top result for the phrase sagemaker GAN
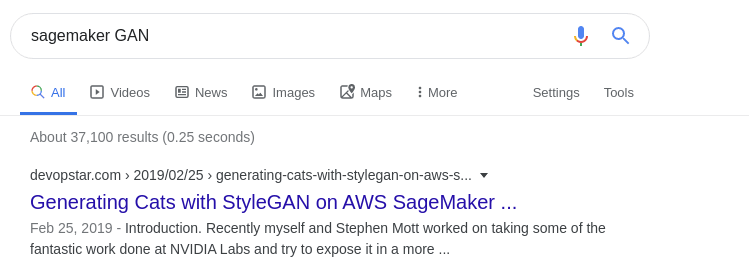
Google and other search engines will index links based on a number of hidden variables and rank them accordingly. You can see that my site in particular ranks really well for those keywords so Google will invite guests looking for information on that topic to my site.
WordPress had a very particular link structure for blog posts that used the date and a slug to define the URL. The example above can be seen below:
https://devopstar.com/{year}/{month}/{day/{slug}/When moving our sites contents it is crucial that we maintain the same post structure or alternatively redirect requests to the origin URL. For example, perhaps you wanted to change the URL to be the following:
https://devopstar.com/{slug}/You need to ensure that the original URL redirects to the new URL or risk losing your ranking with major search providers.
URL Formatting
When moving DevOpStar I opted to instead keep the same URL structure as what I had on WordPress. This meant I needed to customize the page URLs when creating blogs within the GatsbyJS configuration.
To achieve this I made the following changes to my gatsby-node.js config:
exports.onCreateNode = ({ node, getNode, actions }) => {
const { createNodeField } = actions;
if (node.internal.type !== 'MarkdownRemark') return;
// Parse date for URL
const itemDate = new Date(node.frontmatter.date);
const itemYear = itemDate.getFullYear();
const itemMonth = `${itemDate.getMonth() + 1}`.padStart(2, 0);
const itemDay = `${itemDate.getDate()}`.padStart(2, 0);
// sourceInstanceName defined if its a blog or something-else
const sourceInstanceName = fileNode.sourceInstanceName;
// Generate slug depending on sourceInstanceName
if (sourceInstanceName === 'blog') {
slug = `/${itemYear}/${itemMonth}/${itemDay}/${node.frontmatter.slug}`
}
// create slug nodes
createNodeField({
node,
name: 'slug',
// value will be {YYYY/MM/DD/title}
value: slug
});
// adds a posttype field to extinguish between blog and courses
createNodeField({
node,
name: 'posttype',
// value will be {blog||courses}
value: sourceInstanceName
});
}Then in the createPages function of gatsby-node.js I simply referenced the slug field when defining the URL to be used for the blog page
...
// create each individual blog post with `blogPostTemplate`
createPage({
path: node.fields.slug,
component: blogPostTemplate,
context: {
slug: node.fields.slug
}
})
...Cache Headers
To ensure that caching on the client is respected it is always advisable to define your own max-age on content served by your site. If you deployed your site using the previous post Migrating WordPress to GatsbyJS - Architecture & CI/CD then you would have noticed a block in the CDK code defining cache_headers.
We make use of an awesome service Amazon CloudFront offers called Lambda@Edge which effectively passes the requests made to your site through a Lambda function that can perform manipulation on the request.
I used a fantastic example from Joris Portegies Zwart in the post Hosting a Gatsby site on S3 and CloudFront for the following examples.
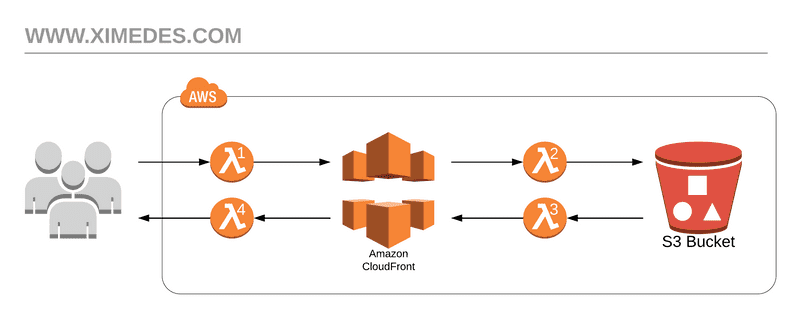
We add a lambda function with the following code to the ORIGIN_RESPONSE (denoted as λ3 in the diagram). This code will add a large max age to any files places in the static asset directory, and set the cache on all other assets to always refresh.
'use strict';
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
const response = event.Records[0].cf.response;
const headers = response.headers;
if (request.uri.startsWith('/static/')) {
headers['cache-control'] = [
{
key: 'Cache-Control',
value: 'public, max-age=31536000, immutable'
}
];
} else {
headers['cache-control'] = [
{
key: 'Cache-Control',
value: 'public, max-age=0, must-revalidate'
}
];
}
callback(null, response);
};index.html Redirects
The second issue we needed to solve was to append index.html onto the end of requests to the S3 bucket content. The problem occurs when the client refreshes a request to a url without denoting a html file on the end. For example the url http://devopstar.com/2020/02/03/migrating-wordpress-to-gatsby-js-search-engine-optimization doesn't include index.html, so when CloudFront tries to return a file to the client, it attempts to instead return the folder object for the slug.
To fix this we should add an ORIGIN_REQUEST (denoted as λ2 in the diagram) so that requests made from CloudFront that don't include index.html have it appended for us. The code for this can be seen below and is very straight forward.
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
const uri = request.uri;
if (uri.endsWith('/')) {
request.uri += 'index.html';
} else if (!uri.includes('.')) {
request.uri += '/index.html';
}
callback(null, request);
};Legacy Redirects
We can extend the code above to also include a way to redirect legacy requests and correctly handle endpoints that might no longer exist in the GatsbyJS site.
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
const uri = request.uri;
// Redirect results to their new pages
const redirects = [
{ test: /^\/shop\/?$/g, targetURI: '/' },
{ test: /^\/about-us\/?$/g, targetURI: '/#about' },
{ test: /^\/contact\/?$/g, targetURI: '/#contact' },
{ test: /^\/faqs\/?$/g, targetURI: '/' },
];
const redirect = redirects.find(r => uri.match(r.test));
if (redirect) {
const response = {
status: '301',
statusDescription: 'Moved Permanently',
headers: {
location: [
{
key: 'Location',
value: 'https://devopstar.com' + redirect.targetURI
}
]
}
};
callback(null, response);
return;
}
// Make sure directory requests serve index.html
if (uri.endsWith('/')) {
request.uri += 'index.html';
} else if (!uri.includes('.')) {
request.uri += '/index.html';
}
callback(null, request);
};When requests are made to the URLs defined in the redirects array, a redirection is forced to the new location. These redirect handlers are very important for SEO and most search engines will penalize you if you do not handle them correctly.
Attribution
A very large portion of this post was based on the amazing work in the Hosting a Gatsby site on S3 and CloudFront post. I highly recommend checking their work out if you need further advice about serving GatsbyJS via CloudFront.
Summary
The content covered in this post is far from complete as there are endless amounts of things you can do to continue to improve. I hope at the very least I have gotten you to think more seriously about SEO and how it can improve your website rating in the eyes of search engines.