Let's Try - Amazon Athena Partition Projections


Updated 1st October 2023: Added a section on
enumpartition projections and how they can be used to query data without knowing the partitioned value.
Introduction
Amazon Athena's partition projections are an essential tool for those diving deep into data analytics. While the official documentation provides a comprehensive overview, I felt there was room for some hands-on examples.
This post aims to bridge that gap, offering practical demonstrations from the basics to more advanced scenarios, simplifying the learning process for many.
Why Partition Projections?
Partition projections in Amazon Athena are a modern solution designed to address several challenges faced by data engineers and analysts. Let's say you've set up your Athena table without specifying partitions:
CREATE EXTERNAL TABLE website_logs (
user_id STRING,
action STRING,
timestamp TIMESTAMP
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://website-logs/';Now, if logs are written to S3 daily, or even multiple times a day, you'd get directories like:
s3://website-logs/year=2023/month=09/day=24/
s3://website-logs/year=2023/month=09/day=25/Instead of manually adding each partition with ALTER TABLE, you'd just periodically run:
MSCK REPAIR TABLE website_logs;This command would automatically add the new partitions to the table. However, this approach has several drawbacks:
- Performance: On large datasets with thousands of partitions,
MSCK REPAIR TABLEcan be slow. - Cost: Athena charges based on the amount of metadata it retrieves. If you have many partitions, this can be cost-inefficient.
- Maintenance: While it's more automated, you still need to remember to run it regularly. If you query the table before running the command, you might miss out on new data.
There is a better way to handle partitioned data in Athena - Partition Projections.
Load Sample Data
I've gone ahead and created a short script that created some synthetic data and uploaded it to S3. You can find the script here. Open a terminal and run the following commands:
# Download the script, make it executable
curl https://gist.githubusercontent.com/t04glovern/b751378c246bca8d8b1149b5a2450790/raw \
> partition-projection-synthetic-data.py \
&& chmod +x partition-projection-synthetic-data.py
# Install the dependencies
pip3 install boto3
# Create a bucket (replace <bucket-name> with your bucket name)
aws s3 mb s3://<bucket-name>
# Run the script (replace <bucket-name> with your bucket name)
./partition-projection-synthetic-data.py --bucket <bucket-name>Running this script should give you a bucket with the following structure:
robocat/
├─ 1/
│ ├── year=2023/month=07/day=01/
│ │ ├── hour=00/ -> 2023-07-01_00-00-00_XXXX.jsonl.gz, ...
│ │ ├── hour=01/ -> ...
│ │ ├── ...
│ │ └── hour=23/ -> ...
├─ 2/
│ ├── year=2023/month=07/day=01/
│ │ ├── hour=00/ -> 2023-07-01_00-10-00_XXXX.jsonl.gz, ...
│ │ ├── hour=01/ -> ...
│ │ ├── ...
│ │ └── hour=23/ -> ...An example of the data inside one of the jsonl.gz files can be seen below for reference as well
{
"id": "1",
"timestamp": "2023-07-01T00:00:05.123456Z",
"speed": 45,
"temperature": 25.1,
"location": {"lat": -31.976056, "lng": 115.9113084}
}Checking your bucket in the AWS console should look something like this:
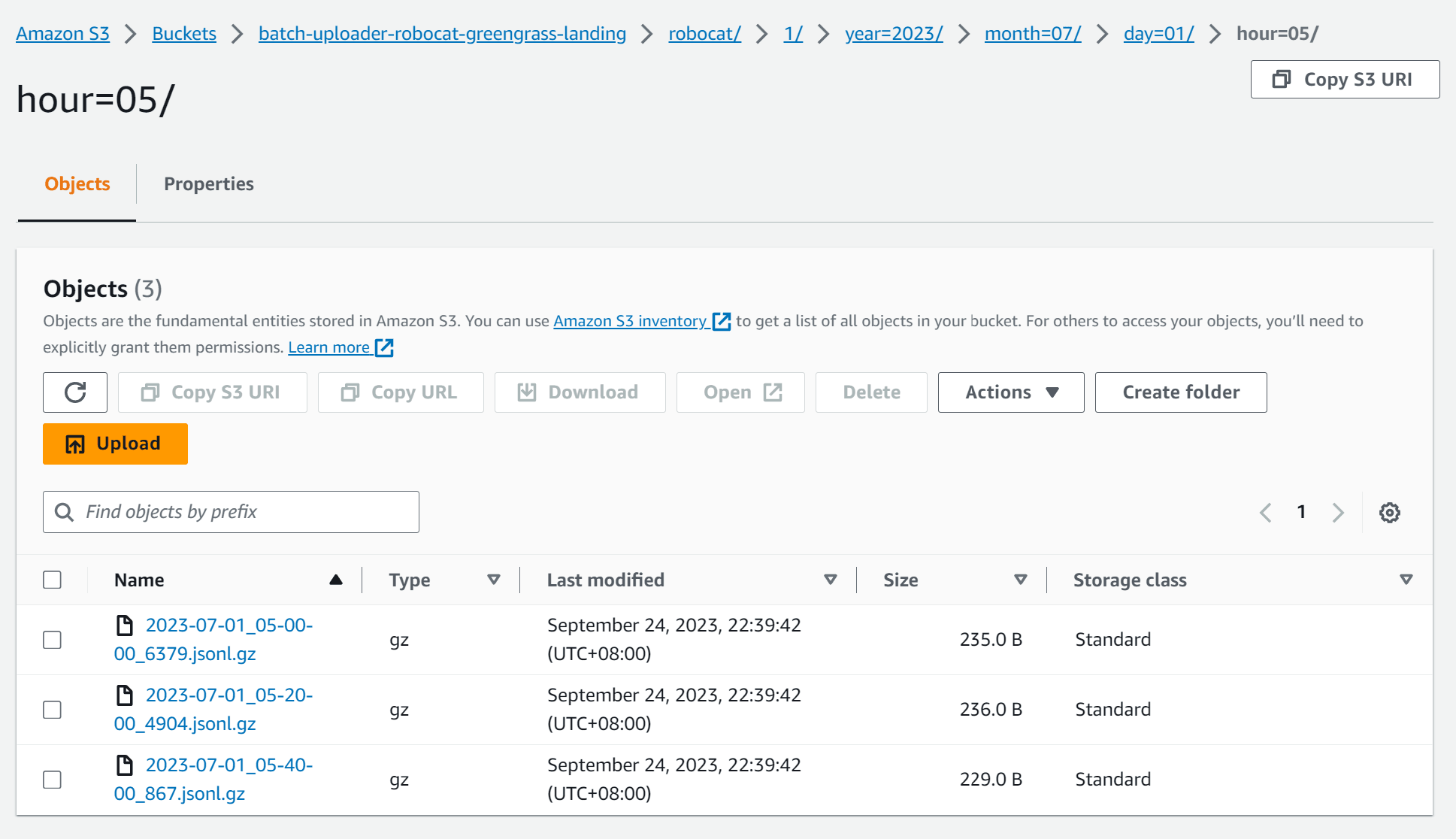
If you are observant you will notice that the data is partitioned by year, month, day and hour. This is important as we will be using these partitions to demonstrate partition projections.
Data is also placed into folders based on the id of the device that generated the data. We will demonstrate how partitioning can be used to filter data based on this id as well.
Exploring Partition Projection CREATE TABLE Statement
Now that we have some data to work with, we can create an Athena table to query it. We will be using the Amazon Athena Console to create the table.
Note: When running the
partition-projection-synthetic-data.pyscript, two SQL files are generated. These files contain the SQL statements to create the final partition projected table and a query to test the table - If you feel like skipping ahead!
Partition Projections are a powerful way to eliminate the need for manual partition management. They can also optimize the performance of certain query patterns by reducing the amount of data Athena needs to scan. Let's dissect our partition projection creation statement.
CREATE EXTERNAL TABLE IF NOT EXISTS partition_projection_sample_data (
`id` string,
`timestamp` timestamp,
`speed` int,
`temperature` float,
`location` struct<lat: float, lng: float>
)This section defines the main data columns in the table. We have an id, timestamp, speed, temperature, and the location stored as a struct with lat and lng. This is the same structure as the data in the jsonl.gz files. None of the above should be new to you if you've done SQL before.
PARTITIONED BY (
device_id string,
year int,
month int,
day int,
hour int
)Here, we've defined our partitions. While device_id, year, month, day, and hour will be mapped as columns in our Athena table, they aren't directly present as fields inside the data files. Instead, they are derived from the S3 directory structure where the data resides.
This means, rather than storing these values in each and every data record (which could be redundant and inefficient), we leverage the inherent organization of our data in S3 to extract these values, providing us fine-grained control over our data slices.
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
WITH SERDEPROPERTIES ( "timestamp.formats"="yyyy-MM-dd'T'HH:mm:ss.SSSSSSZZ" )The data is serialized in JSON format, and with SERDEPROPERTIES, we've defined the format for our timestamp to ensure correct deserialization.
LOCATION 's3://<bucket-name>/robocat/'This specifies where Athena should look in S3 for the data. All the files under this location are included in the table.
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.device_id.type" = "injected",
"projection.year.type" = "integer",
"projection.year.range" = "2023,2033",
"projection.month.type" = "integer",
"projection.month.range" = "1,12",
"projection.month.digits" = "2",
"projection.day.type" = "integer",
"projection.day.range" = "1,31",
"projection.day.digits" = "2",
"projection.hour.type" = "integer",
"projection.hour.range" = "0,23",
"projection.hour.digits" = "2",
"storage.location.template" = "s3://<bucket-name>/robocat/${device_id}/year=${year}/month=${month}/day=${day}/hour=${hour}"
);The TBLPROPERTIES section is where the magic of partition projection happens:
- "projection.enabled" = "true": This enables the partition projection feature.
- "projection.device_id.type" = "injected": The device_id is inferred from the S3 path.
- injected: The partition value needs to be injected into the query in a WHERE clause.
- year, month, day, and hour projections are set as integer, with their respective ranges and digits specified.
- range: The range of values for the partition - example: 1,12 for month.
- digits: The number of digits in the partition value - example: 2 for 01, 03, 10, 12.
- "storage.location.template": defines the S3 path structure for Athena to find the data. The $ placeholders are dynamically replaced by the corresponding partition values during a query, guiding Athena directly to the right S3 location.
Exploring Partition Projection SELECT Query
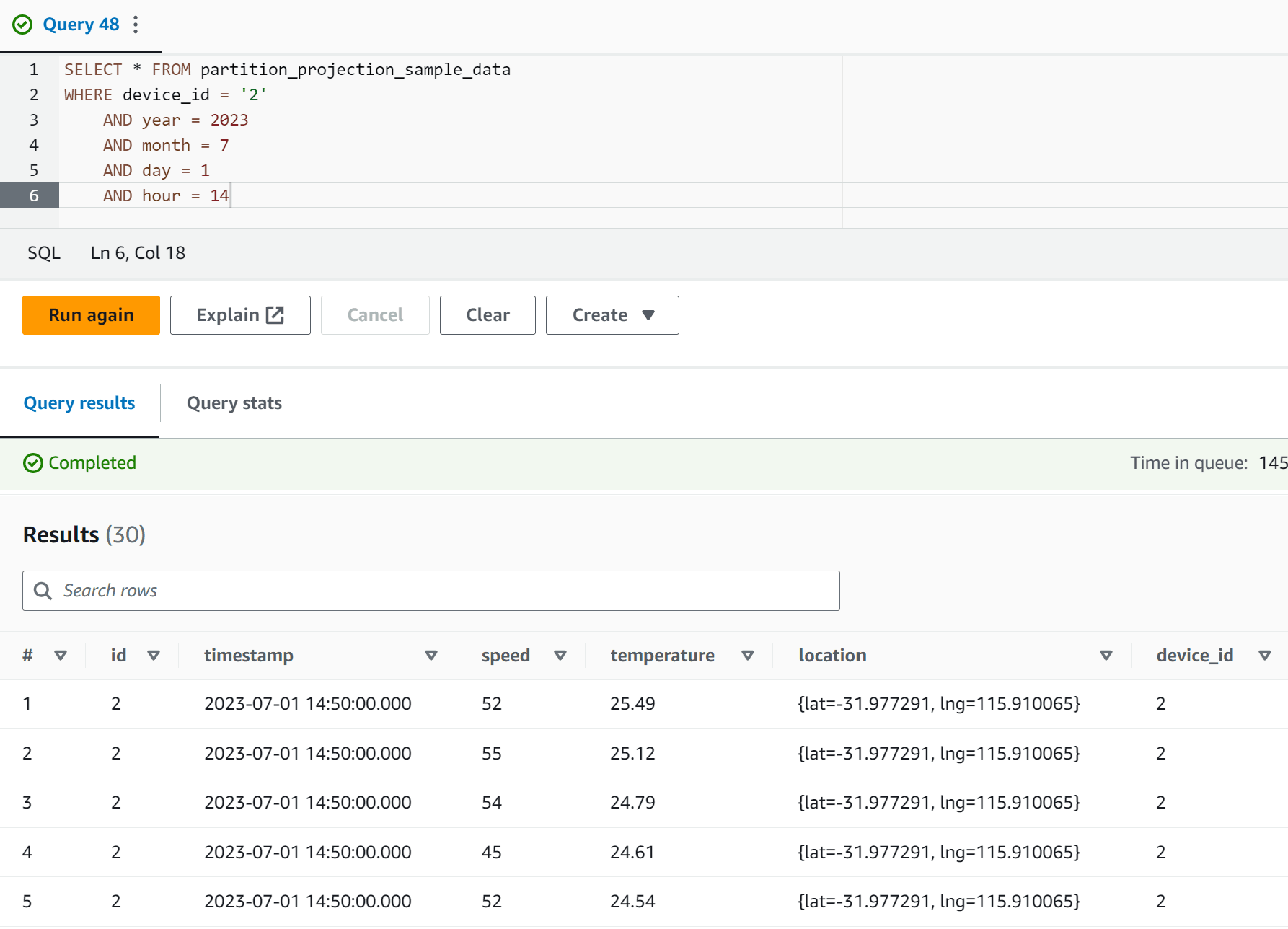
Having set up our Athena table with partition projection, let's see how it affects our SELECT statements. The given query:
SELECT * FROM partition_projection_sample_data
WHERE device_id = '2'
AND year = 2023
AND month = 7
AND day = 1
AND hour = 14Now, let's break down the query:
- FROM partition_projection_sample_data: This specifies the table we want to query.
- WHERE device_id = '2': This part of the query demonstrates the power of partition projection. Instead of scanning all the data, Athena immediately knows to narrow the search to files inside the
2/directory. - The subsequent conditions - year = 2023, month = 7, day = 1, hour = 14 - work in a similar fashion. Athena utilizes the path structure specified during table creation to quickly locate the data. With the given constraints, Athena can precisely pinpoint to
s3://<bucket-name>/robocat/2/year=2023/month=07/day=01/hour=14/and scan only the relevant files.
Enum Partition Projection
The downside of the preious example using injected partition projection is that if you don't know the partitioned value being injected, you can't query the data. If you attempt to run the query below you should see an error.
SELECT * FROM partition_projection_sample_data
WHERE year = 2023
AND month = 7
AND day = 1
AND hour = 14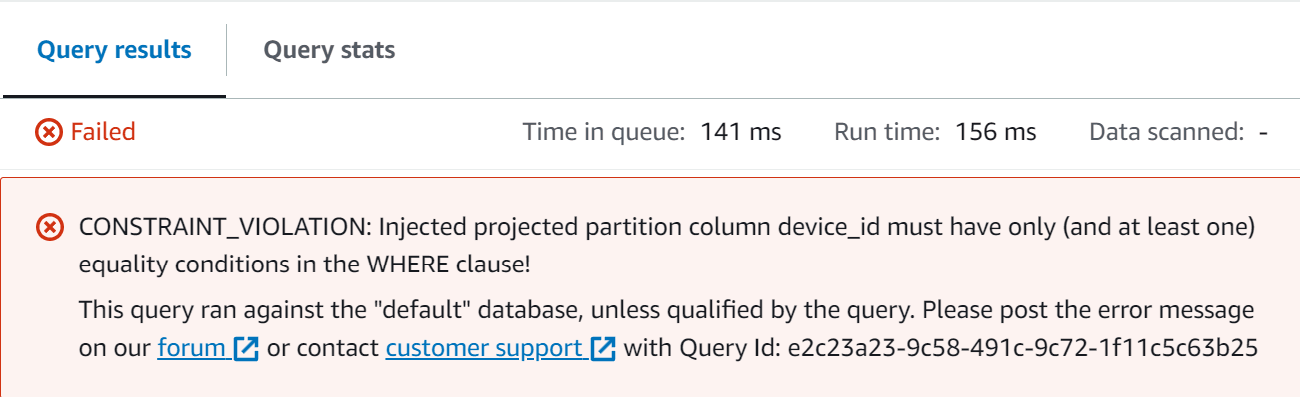
This is where it is useful to use an enum partition projection. This allows you to query the data without knowing the partitioned value - however it also requires you to define the partitioned values up front.
For example, we would need to explicitely define ALL values of device_id in order to benefit from partition projection - If we had 1000s of devices this method is unlikely to be practical.
See how we can define an enum partition projection below - take note of the projection.device_id.type|values properties.
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.device_id.type" = "enum",
"projection.device_id.values" = "1,2",
"projection.year.type" = "integer",
"projection.year.range" = "2023,2033",
"projection.month.type" = "integer",
"projection.month.range" = "1,12",
"projection.month.digits" = "2",
"projection.day.type" = "integer",
"projection.day.range" = "1,31",
"projection.day.digits" = "2",
"projection.hour.type" = "integer",
"projection.hour.range" = "0,23",
"projection.hour.digits" = "2",
"storage.location.template" = "s3://<bucket-name>/robocat/${device_id}/year=${year}/month=${month}/day=${day}/hour=${hour}"
);Now, if we run the same query as before, we should see the results as expected.
SELECT * FROM partition_projection_sample_data
WHERE year = 2023
AND month = 7
AND day = 1
AND hour = 14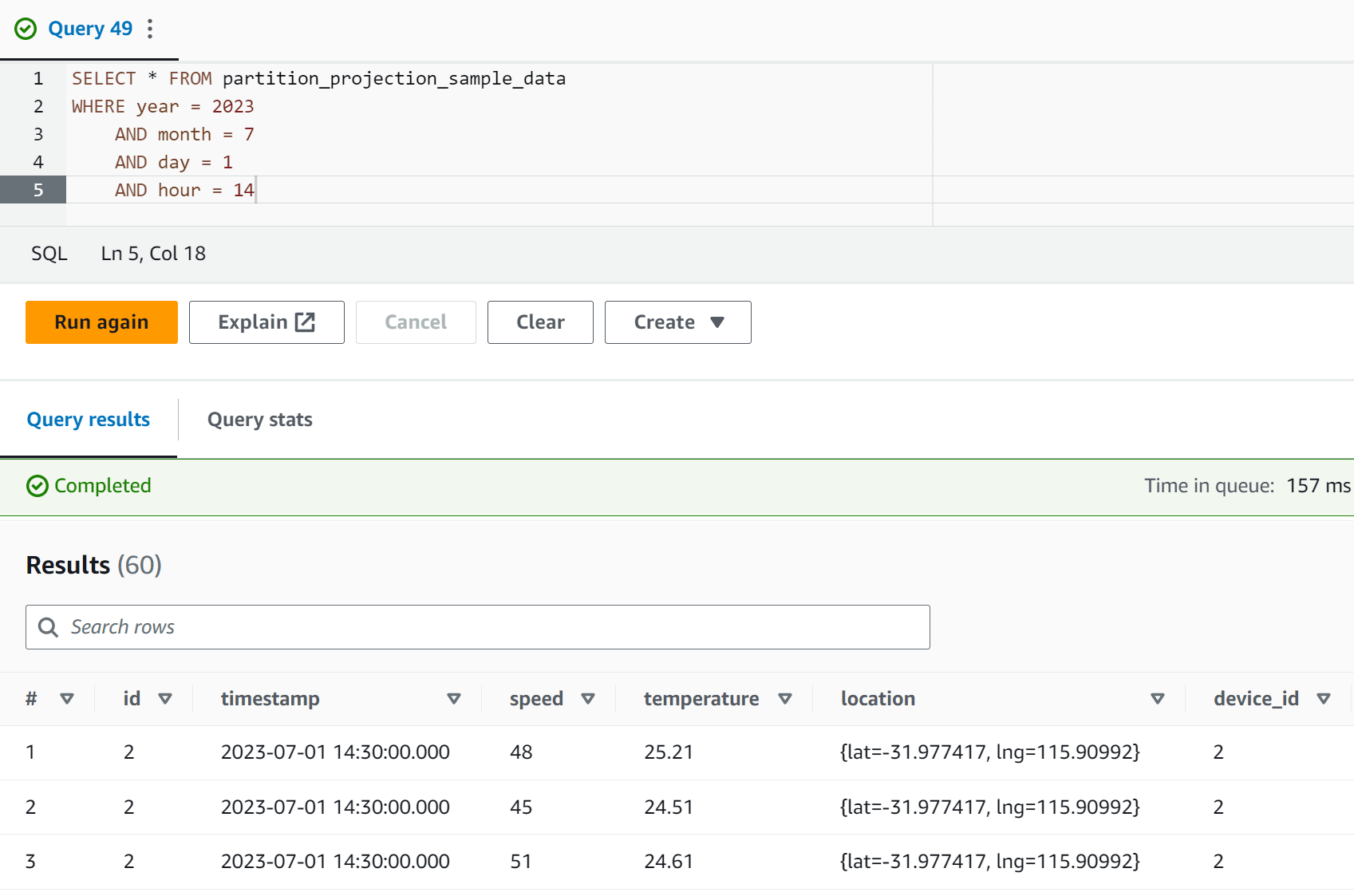
And, we are still able to query the data using the device_id qualifier as well - giving us the best of both worlds.
SELECT * FROM partition_projection_sample_data
WHERE device_id = '1'
AND year = 2023
AND month = 7
AND day = 1
AND hour = 14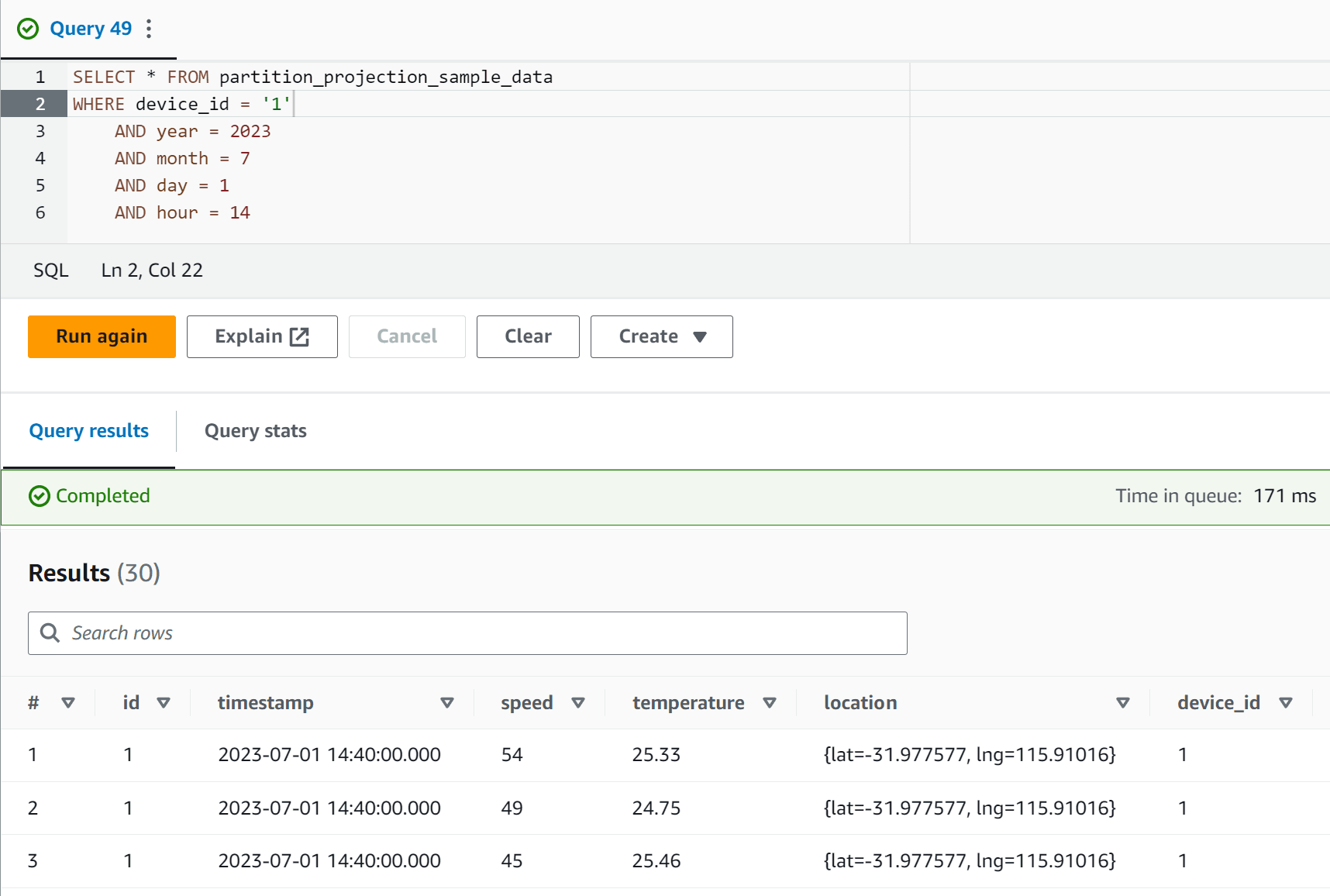
Summary
The benefits of partition projections are evident here:
- Reduced Costs: Since Athena charges based on the amount of data scanned, narrowing down the scan to only the necessary files can significantly reduce costs.
- Improved Performance: Reducing the volume of data scanned speeds up the query execution.
Partition Projections in Athena provide a streamlined way of handling partitioned data, making the management process more straightforward and dynamic. With this feature, Athena can intuitively navigate through the directory structure, ensuring optimal performance and cost-effectiveness.
As seen in the example, Athena uses the defined table properties to limit data scans, resulting in faster queries and minimized costs. This feature is a testament to how cloud services like Amazon Athena continue to evolve, simplifying data operations while maximizing efficiency.
If you have any issues or feedback please feel free to reach out to me on Twitter @nathangloverAUS or leave a comment below!