Why You Need to Care About Apache Iceberg Optimization


Introduction
When I first started working with Apache Iceberg two years ago, I was blown away by the capabilities it offered. The cost and performance benefits of using the Iceberg table format over traditional storage formats like Parquet were immediately apparent to me. It seems like magic that you can do things like change schema, partitions and even rollback to previous versions of your data with ease - all on top of a well-understood storage backend like S3.
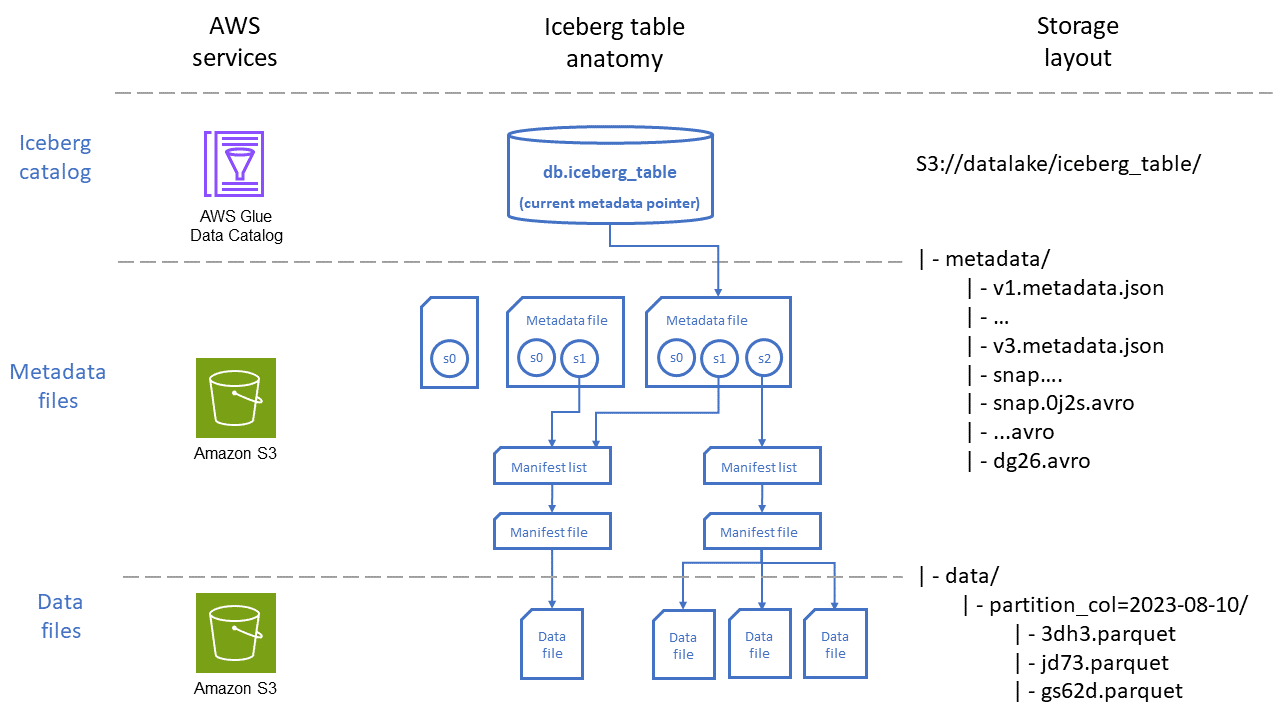
However, these incredible features come at a cost. The Iceberg table format works by storing metadata and data separately and creating a new version of the metadata and data files every time you write to the table. This means that over time, the number of files in your Iceberg table storage bucket can grow exponentially. This can lead to performance issues when querying the table, as the number of files that need to be read can slow down the query. It can also lead to significant costs that can just appear out of nowhere.
I have personally seen what happens... We had unexpected high frequency inserts occur on an Iceberg table that resulted in the number of snapshots being generated to cause cost spiral - where the size of the metadata file grew to over +1GB each, so each insert was creating a new 1GB file. Eventually the inserts were taking so long that the table became unstable and queries were timing out.
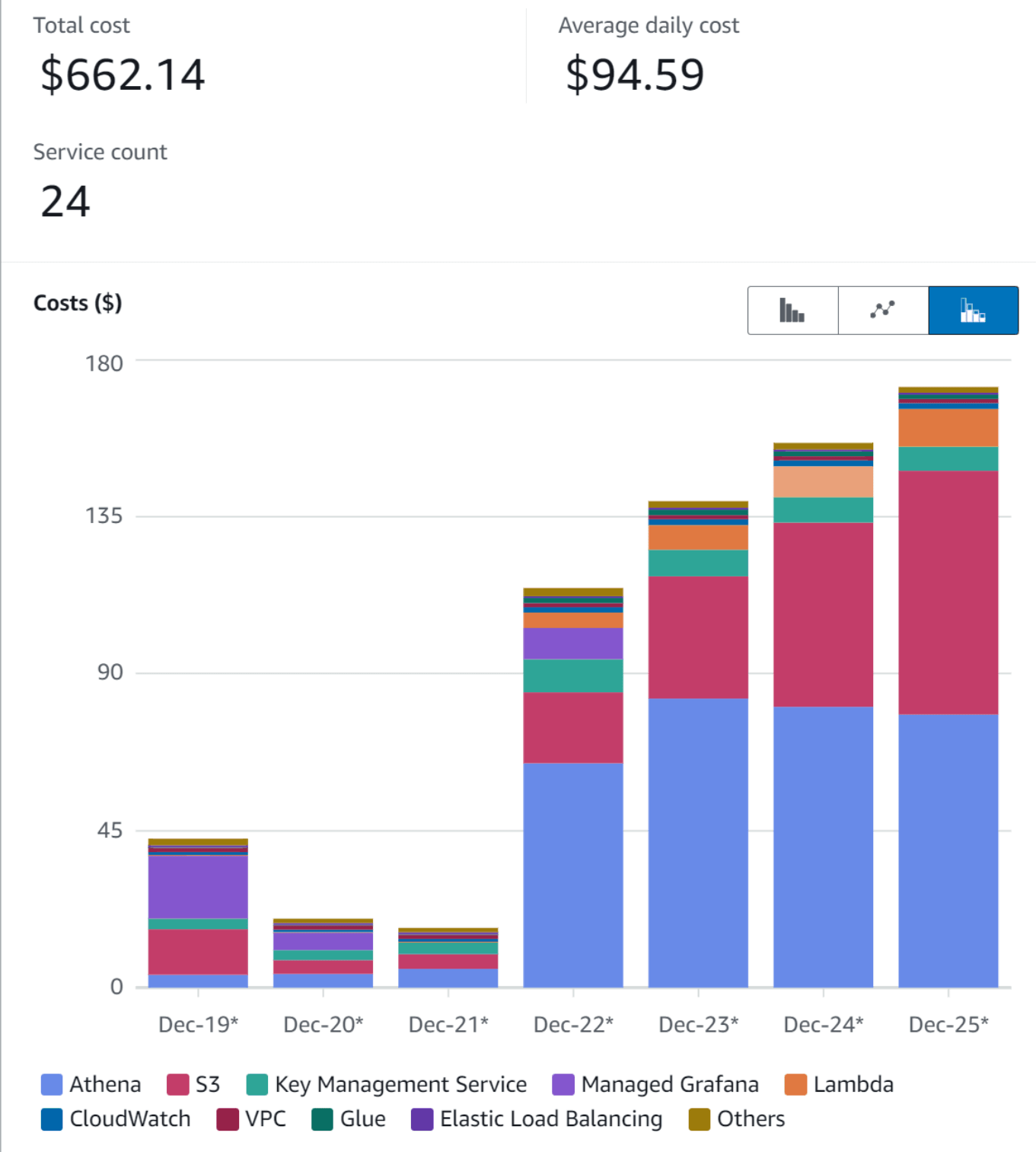
This issue occurred due to table maintenance happening too infrequently and with settings that were not tailored to the the frequency of the inserts.
Table maintenance for Iceberg is almost a full-time job in itself. Especially when you start to have many tables and many teams. This is where the new optimization features in AWS Glue come in.
Three Problems with Iceberg Storage
Right now there are three main problems that are not particularly ovbvious initially when customers start using Iceberg:
Snapshot Retention - The problem I described at the start of this article. Apache Icebergs greatest strength can also be its greatest weakness. The ability to rollback to previous versions of your data is great, but the cost is storage and metadata. If there is no good reason to keep snapshots after a certain period of time, they need to be expired.
The follow up problem to this is that while a snapshot might be expired, the data and metadata files are still present in the storage bucket. An operation aptly called a VACUUM is required to clean up these files, and this is not something that is done automatically for you in Iceberg, as Iceberg is a table format, not a database engine.
Compaction - The Iceberg table format works by storing metadata and data separately and creating a new version of the metadata and data files every time you write to the table. This means that if you write a single record to the table, you will create a new metadata and data file. That data file could literally be a 1kb file. If you did this 100,000 times, you would have 100,000 1kb files. Next time you go to query the table, you will potentially have to read all 100,000 files to get the data you need.
Note: This is also a problem with Parquet and other columnar storage formats, but it's important to be aware that you can't just throw data at Iceberg and expect it to be performant.
Iceberg allows you to define a target file size for the data files contained in the table so that when data is inserted it will roughly be written to files of that size. If you are only batch inserting data, this could be perfect for you. However you will more than likely need to run compaction jobs regularly to re-write the data files to be larger and more performant.
Orphan File Deletion - This is a problem that can occur when if a failure occurs during a write operation to the Iceberg table. Since Iceberg writes are atomic, if something goes wrong during a write, the files could be left in the storage bucket and not referenced by the Iceberg metadata. This problem hide pretty easily as the files are not referenced by the metadata, so you don't have a way to distinguish them.
In this post we will look at how AWS Glue has started to address these problems with three new optimization features.
Pre-requisites
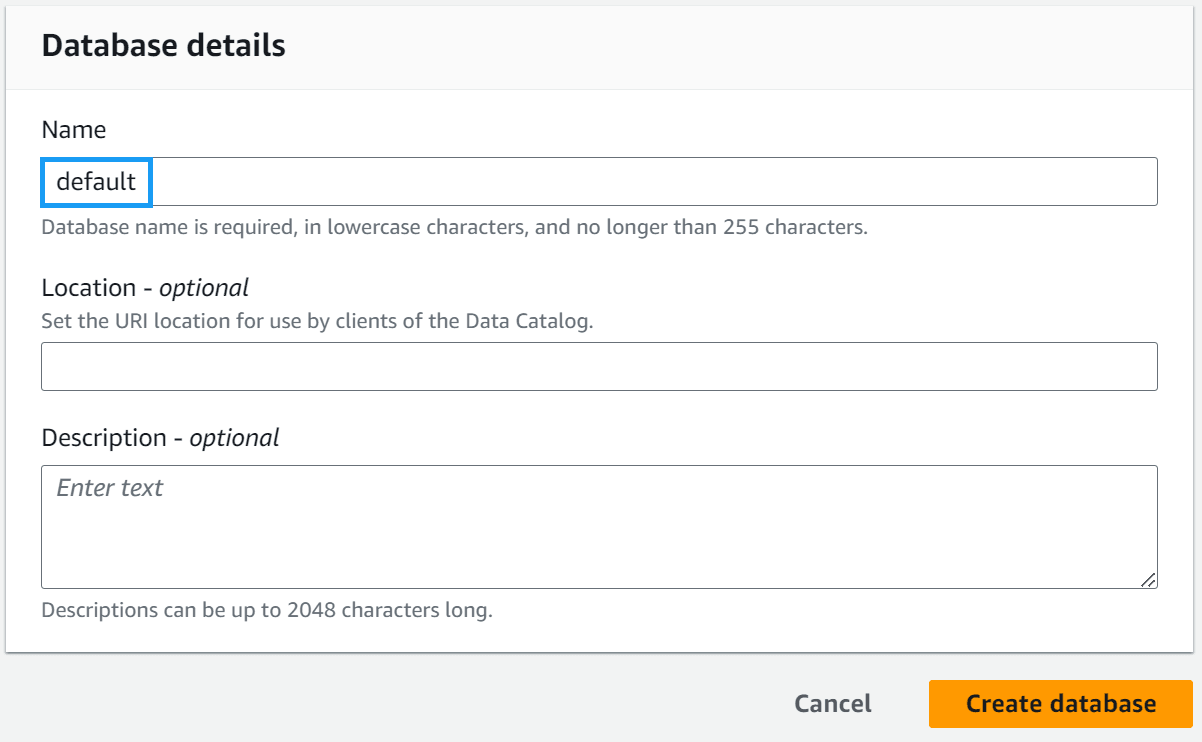
Navigate to the AWS Glue databases console and check to see if you have a database called default. If you do not, create one.
Helper Script
To help demonstrate the new optimization features, I've created a script to do much of the tedious parts of creating an Iceberg table for you. You can find the script here.
Grab the script and run it so you can follow along.
Note: You must set up AWS credentials on your machine for this to work. If you don't have them set up, you can follow the AWS CLI configuration guide.
# Download the script, make it executable
curl https://gist.githubusercontent.com/t04glovern/04f6f2934353eb1d0fffd487e9b9b6a3/raw \
> lets-try-iceberg.py \
&& chmod +x lets-try-iceberg.py
# Create a virtual env (optional)
python3 -m venv .venv
source .venv/bin/activate
# Install the dependencies
pip3 install boto3
# Run the script
./lets-try-iceberg.py --run-queries --optimization --firehoseYou should see something like the following:
# INFO:root:Bucket iceberg-sample-data-729625 does not exist, creating it...
# INFO:root:Running Iceberg table creation query...
# INFO:root:Uploaded samples.jsonl.gz to s3://iceberg-sample-data-729625/sample-data/samples.jsonl.gz
# INFO:root:Running temporary table creation query...
# INFO:root:Running INSERT INTO Iceberg table query...
# INFO:root:Created IAM role lets-try-iceberg-optimization-role
# INFO:root:Created IAM policy lets-try-iceberg-optimization-policy
# INFO:root:Created IAM role lets-try-iceberg-firehose-role
# INFO:root:Created IAM policy lets-try-iceberg-firehose-policy
# INFO:root:Created log group: lets-try-iceberg-log-group
# INFO:root:Created log stream: iceberg
# INFO:root:Role arn:aws:iam::012345678901:role/lets-try-iceberg-firehose-role is now available.
# INFO:root:Created Firehose delivery stream: arn:aws:firehose:us-west-2:012345678901:deliverystream/lets-try-iceberg-streamThis process creates a new Iceberg table, a temporary table and loads sample data into the Iceberg table. It also creates an IAM role and policy for the Glue job and Firehose delivery stream - and creates a Firehose delivery stream which we can use to stream data into the Iceberg table.
Enable Optimization
Head to the Glue console and navigate to the Tables section under Databases. You should see a table called lets_try_iceberg. Click on the table and then click on the Table optimization tab.
Go ahead and click the Enable optimization button.
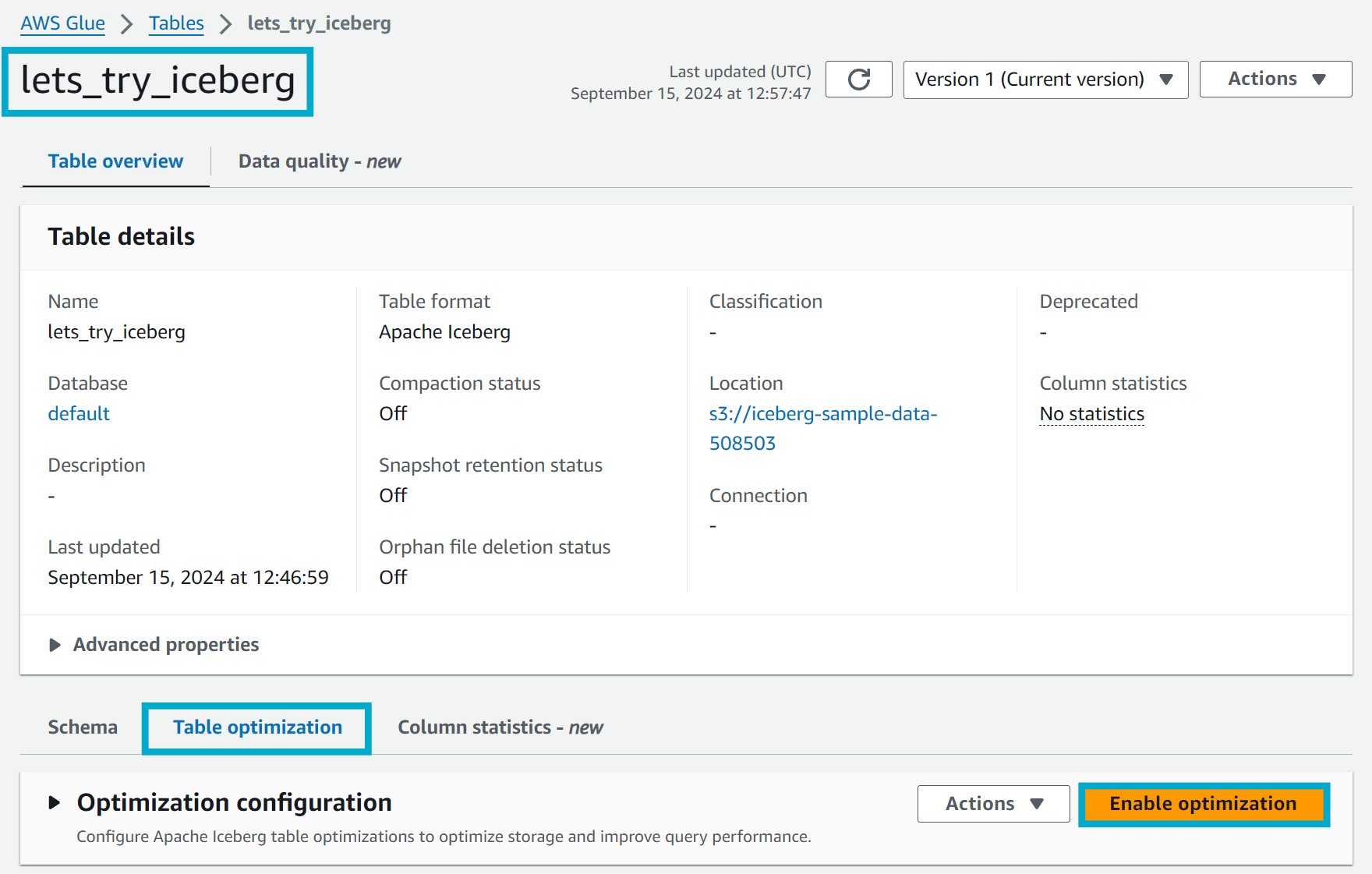
You will be presented with a number of options to configure the optimization. There are currently three different types of optimization available:
- Compaction: Combines small files into larger files so that queries against the table are more efficient.
- Snaptshot retention: Expires snapshots and from the Iceberg table metadata.
- Orphan file deletion: Deletes files that are no longer referenced by the Iceberg metadata but still exist in the iceberg table storage bucket. These are typically created when a failure occurs while writing data to the table.
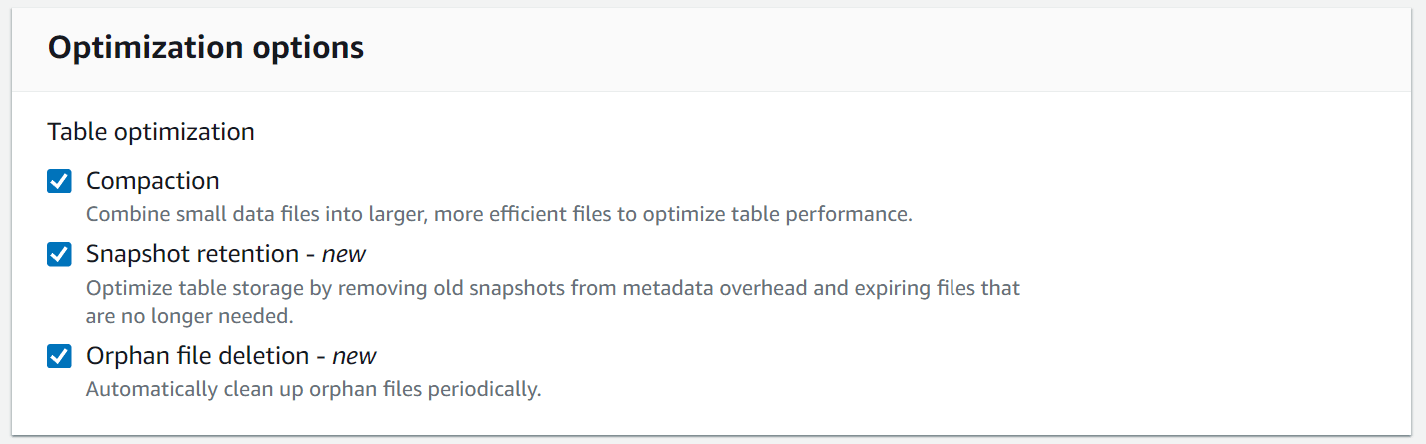
For the purposes of this demo, we will enable all three optimizations at once. under the IAM role dropdown, select the role that was created by the helper script - called lets-try-iceberg-optimization-role. Click Enable optimization to apply the changes.
Note: This action is considered destructive, as it will expire and remove snapshots from the Iceberg table. For this demo this is fine, but please be aware that if you have teams using Iceberg time travel/snapshots, this could be permanently deleting data.
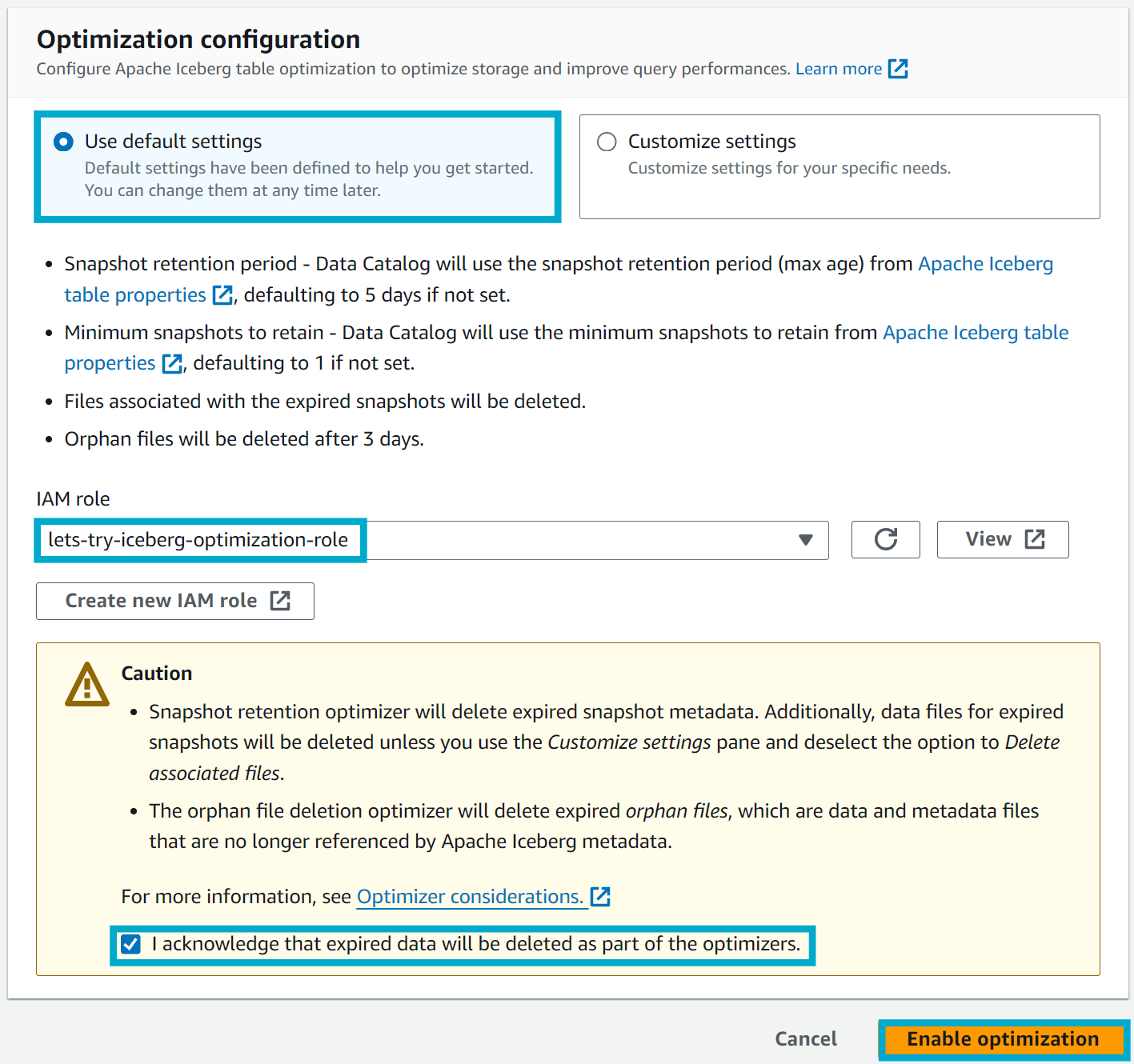
When you enable the optimization - atleast on our demo table - you should see that a snapshot retention and orphan file job is run immediately on the empty table.
To understand when these optimization jobs are going to run, we need to look at the CREATE TABLE sql for the Iceberg table. You can view this by running the following command locally in the same directory as the helper script:
$ cat 1-athena-iceberg-create-table.sqlCREATE TABLE IF NOT EXISTS lets_try_iceberg (
`id` string,
`timestamp` timestamp,
`speed` int,
`temperature` float,
`location` struct < lat: float, lng: float >
)
PARTITIONED BY (
id
)
LOCATION 's3://iceberg-sample-data-729625/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'vacuum_max_snapshot_age_seconds'='60',
'vacuum_max_metadata_files_to_keep'='5'
);We have set the vacuum_max_snapshot_age_seconds to 60 seconds - which is very low for the purposes of this demo (5 days is the default). This means that snapshots with be considered expired after 60 seconds and ready for deletion. Similarly, we have set the vacuum_max_metadata_files_to_keep to 5 - This means only the most recent 5 metadata and data is kept for expired snapshots. This is also considered low for the purposes of this demo (100 is the default).
There is a balance to be struck between how often you want to run these optimization jobs - as they are billed per run and you might find the cost of running the jobs outweights the cost of storing the data.
It's time to generate some data to see this in action. We will use the Firehose delivery stream that was created by the helper script to stream data into the Iceberg table.
./lets-try-iceberg.py --firehose-load
# INFO:root:Successfully put record to Firehose: S9SWNLVTsfNNQ+OyWwaelQtWrN34nc0xRMDntiYkWySHJxnF+iuEbcybKrhwNxlmd1cRBNDcxu5EGoFw87B/Y+j9RBV2bjyqEzAM7cRj85sKVbB3M/4cDyQ4/qoKkXgUpUh6lKoROhbeGaXpxm9vsZM11YXslMayjsRU9CALnpPqTahNmy08e0oCOpTzKmwDb0nVlzDsCXrjTm8dlzXLL9gKSzSSzXZ6
# INFO:root:Successfully put record to Firehose: csq3Jp2RUIOo5VJJt3Lo/3wlkZIy77RLNc/XgybLzm3Ul4qNZ2zsYC5Y7duglcLcO6P3TiJAb+ql09uWTrJiGWxJvcgPgedMZ0/HgqovXqbRn1ErGq2xU+TSUeHdhTOZq9UbjrvNRMzkBMPjDehA4xQahdB3W+bTG5pFpgjUE5ezJI61Hl3K/DHe8DDiABEZdd9SDJ7FIcN0QyIqkKw9VTOq2MJ27CXW
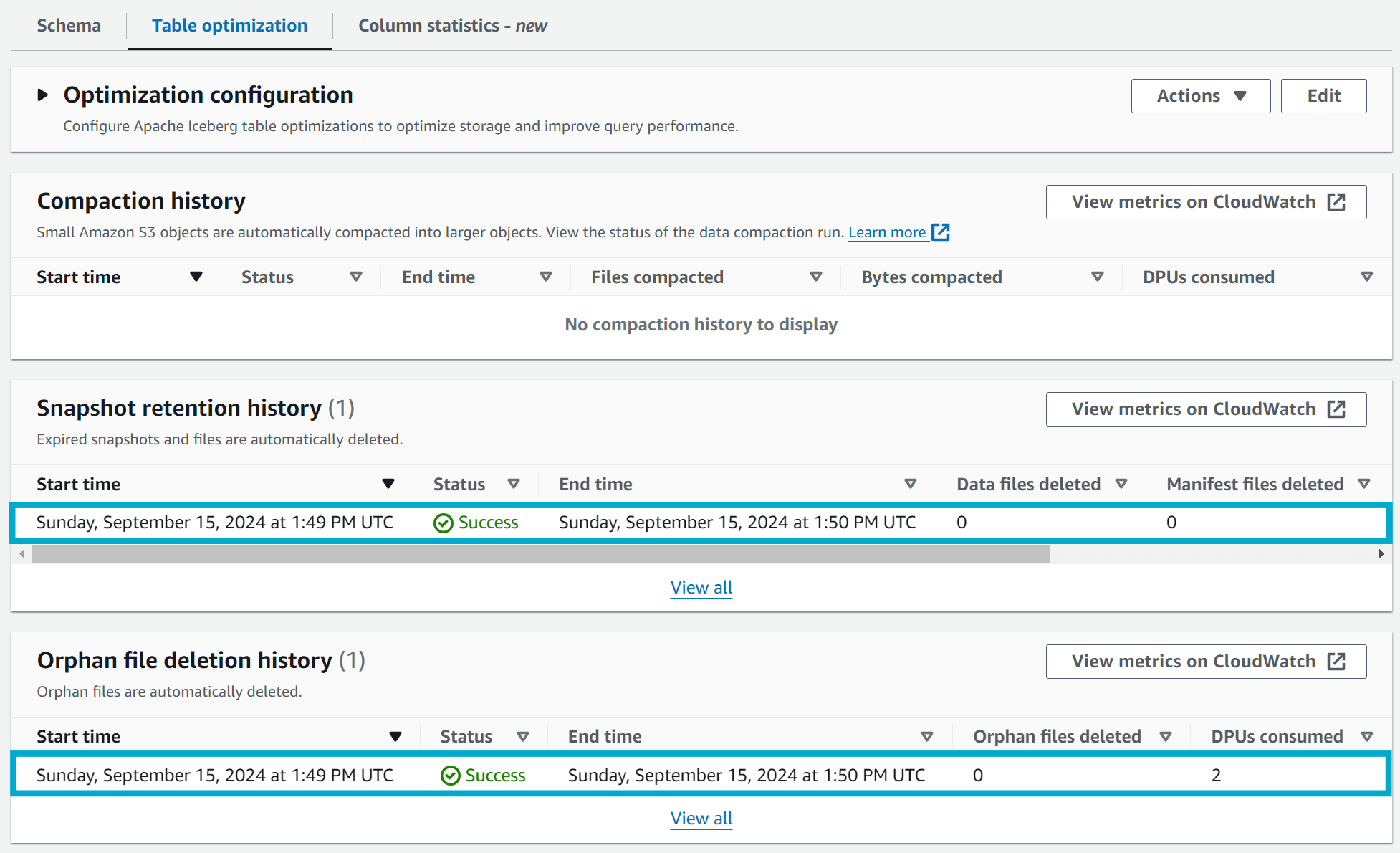
...Go get a cup of coffee and come back in a few minutes. You should now see that the Firehose delivery stream has been writing data to the Iceberg table and compaction jobs have been run. Refresh the Glue table and you should see the following:
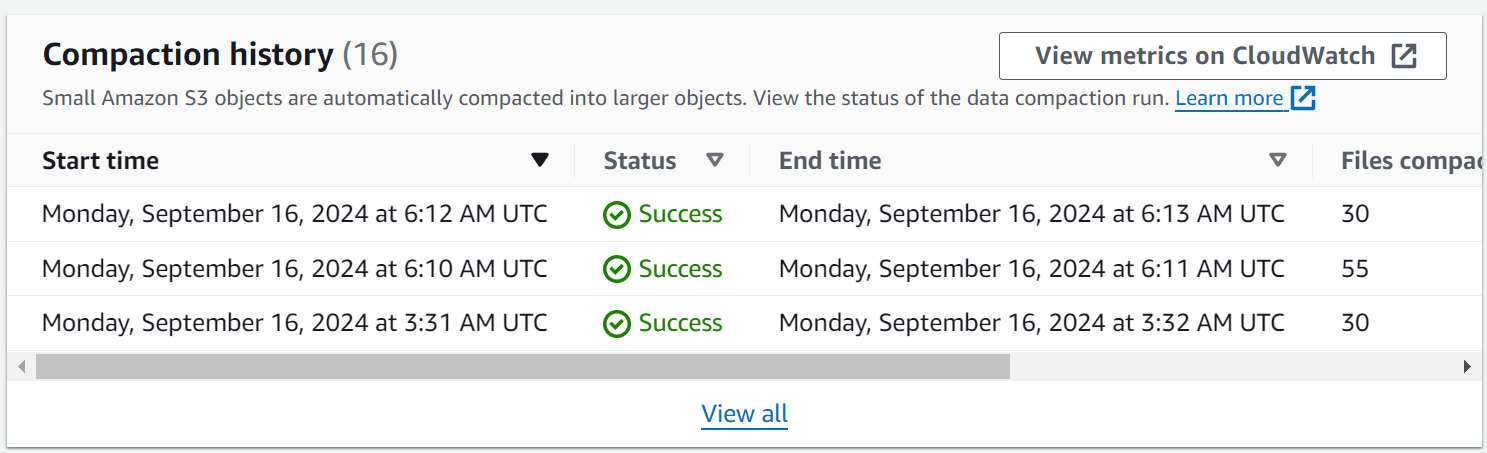
Jumping over to the S3 bucket where the Iceberg table is stored and checking the data and metadata directories however you'll see the problem. The original data and metadata files are still there. This is because the compaction job does not delete the original files, it only creates new files with the compacted data.
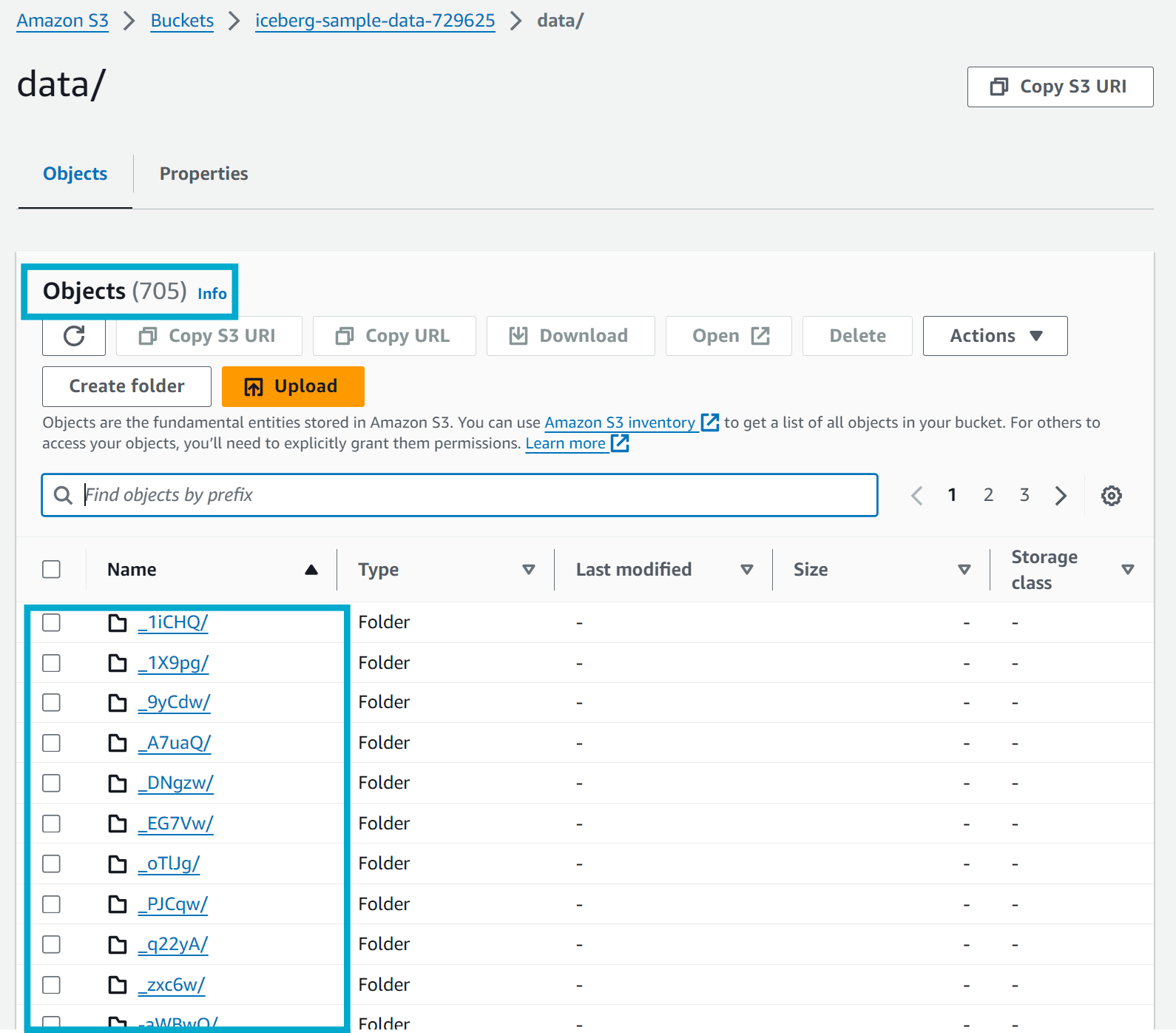
You can further confirm this by running the following Athena query against the Iceberg table which indicates that the number of files actually being used by the Iceberg table is only 5, however the storage bucket has over 705 (in my case) files.
SELECT * FROM "default"."lets_try_iceberg$files";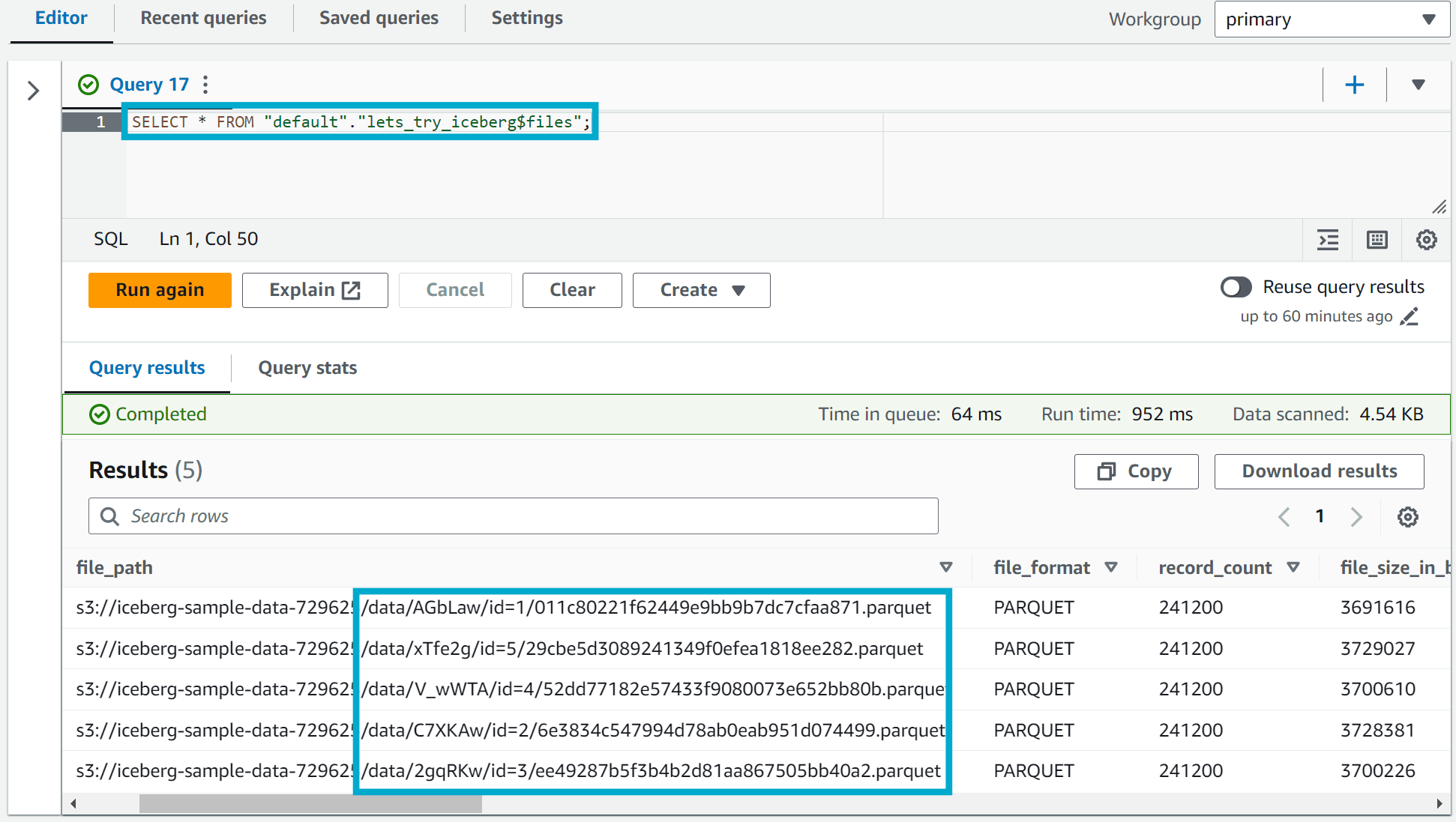
Then next step requires we wait a day for a snapshot retention job to run. It appears you can force a manually trigger by editing the optimization configuration and clicking Enable optimization again.
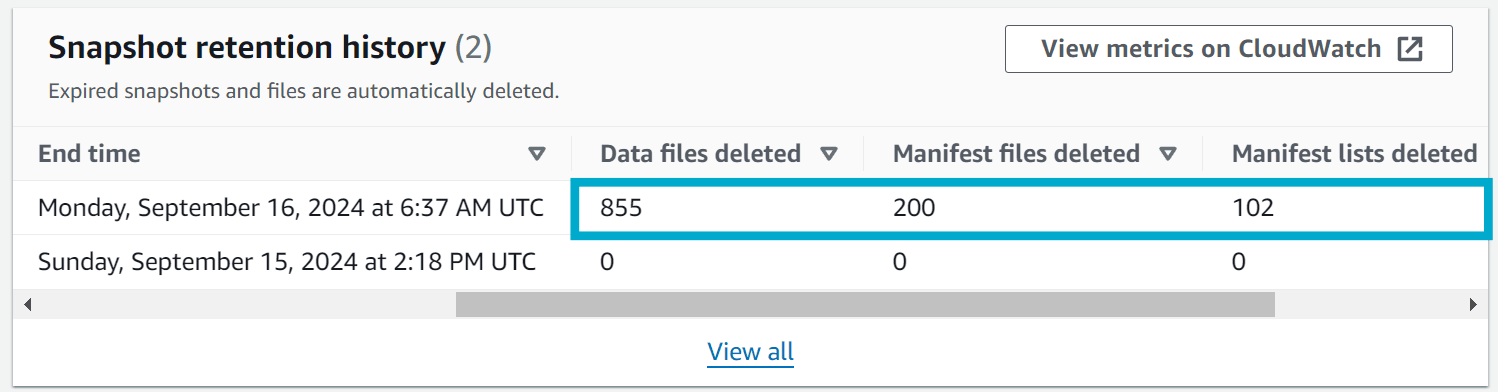
When the job runs, you should see the following in the Glue console under Snapshot retention history. There should be metrics indicating how many data and metadata files were deleted.
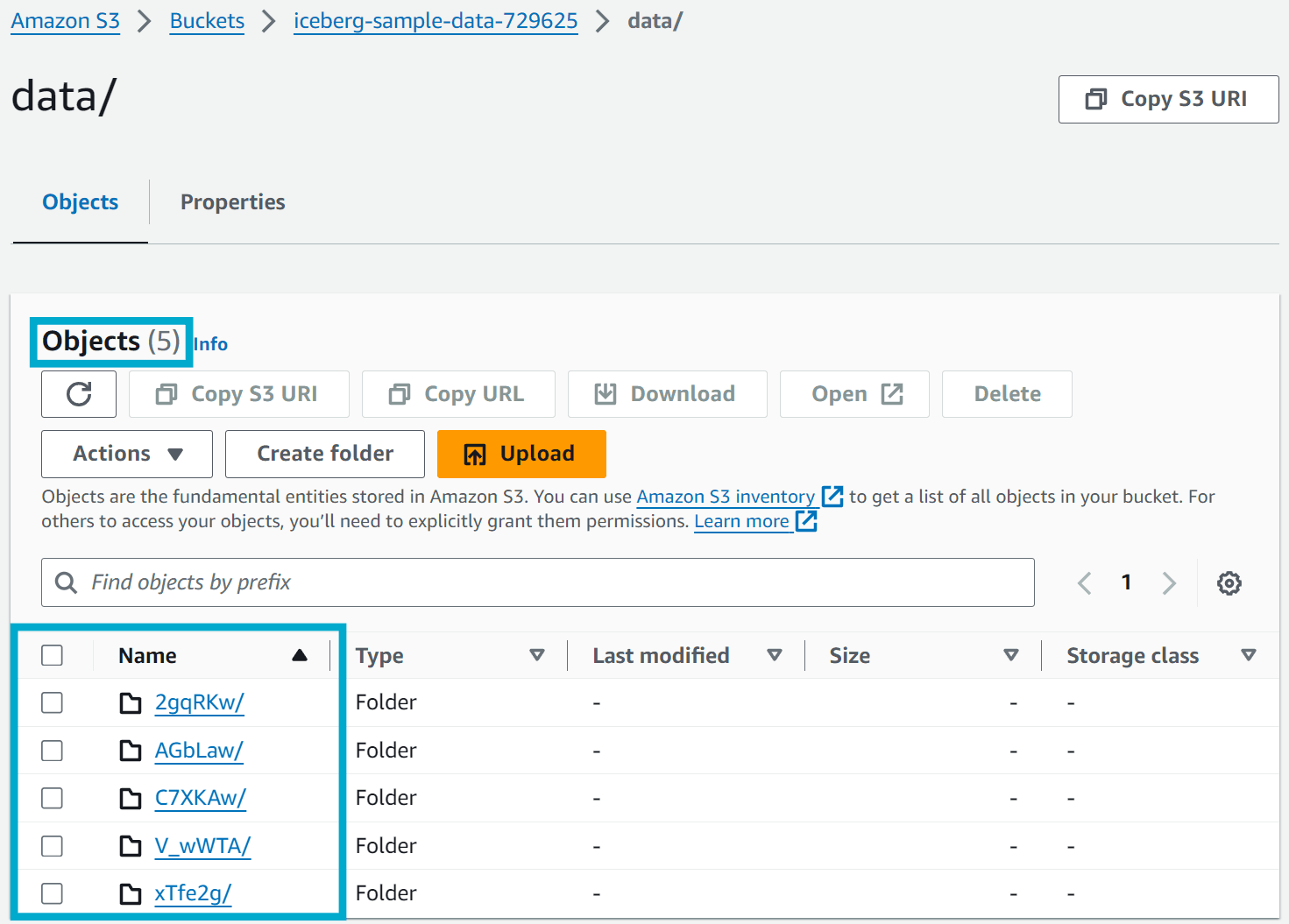
Finally this should be reflected in the S3 bucket where the Iceberg table is stored. The original data and metadata files should be deleted.
Cleanup
I've also included a cleanup script to remove all the resources created by the helper script. Run the following command to clean up the resources:
./lets-try-iceberg.py --deleteSummary
For me these new features are a step in the right direction - but they also raise more questions. I get the feeling that AWS understand that managing Iceberg is not a trivial task and allowing the configuration of when snapshots expire to be done outside of the CREATE TABLE statement potentially allows a governance team to force a standard across all tables.
However, I can foresee this feature costing teams a lot of money if compaction was enabled on a table that has a high frequency writes, but one daily read. In this case it would be far more efficient to purhaps run compaction once a day, but have snapshots expire more frequently.
I believe ultimately that data teams are still going to need to be fluent in Iceberg maintenance and come up with a configuration that works for their use case - but these features are a good start.
If you have any questions, comments or feedback, please get in touch with me on Twitter @nathangloverAUS, LinkedIn or leave a comment below!