Using Claude 3 Haiku as an Eye of Sauron


Introduction
Last year, a handful of AI influencers promised that the future of surveillance would be large language models (LLMs) watching the live security footage and alerting you when something interesting was happening. At the time, people meme'd this idea pretty hard due to the immense cost of running a large language model on video frames, meaning that any startup trying to do this would never operate at a profit.
Fast forward to today. Anthropic's recently unveiled the Claude 3 family of large language models (LLMs), which on paper promise they are highly capable at tasks involving vision - such as image captioning, object recognition, and visual question answering. Claude 3 Haiku stands out as it is far more cost-effective than other models on the market while still offering a vision capability.
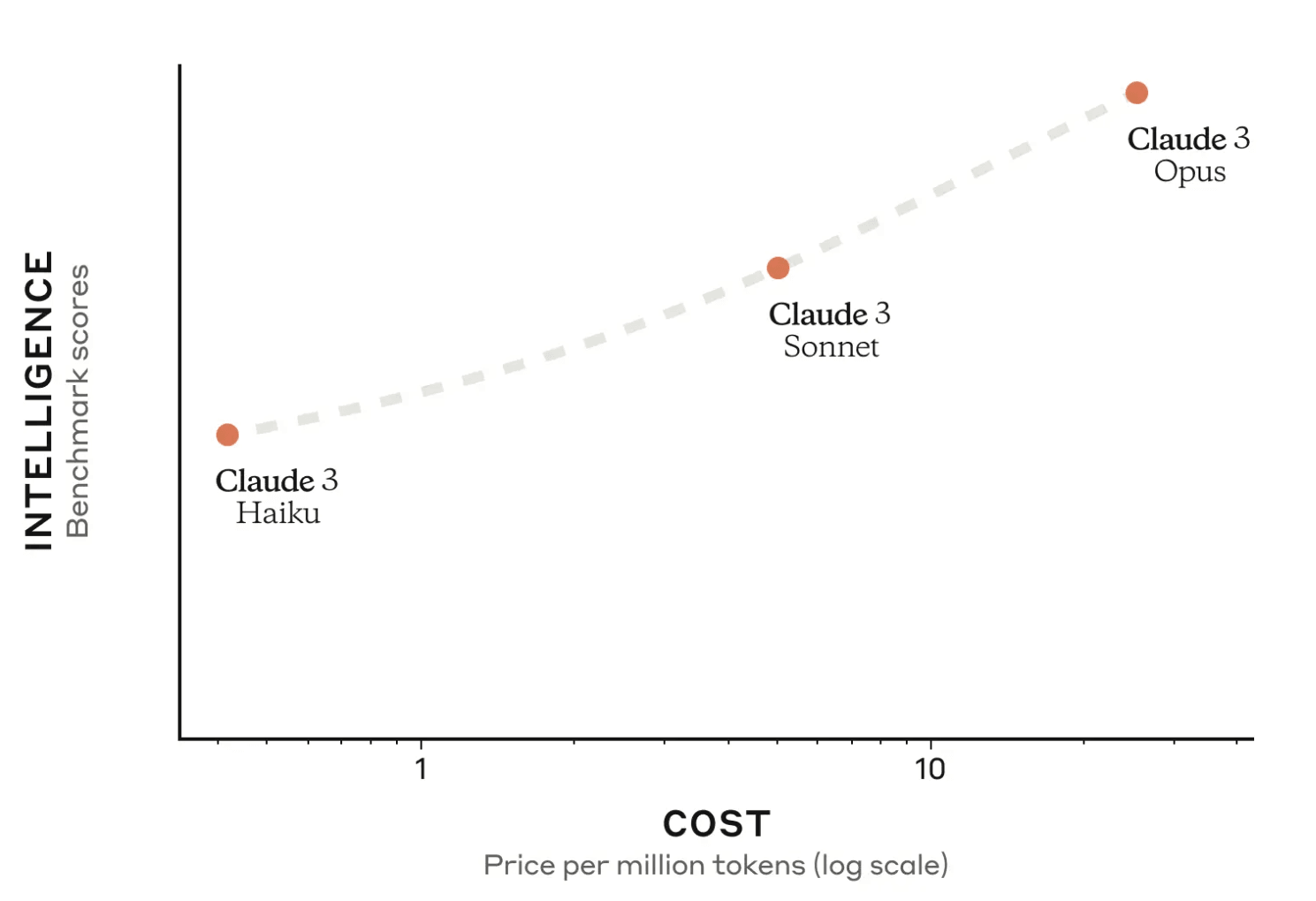
This week (March 2024), Amazon Bedrock has made the Anthropic Claude 3 family available for use in the cloud, and I figured it was time to put this to the test. Were the tech influencers right? Let's find out.
Pre-requisites
If you want to follow along with this tutorial, you will need the following:
- An AWS account
- A Camera video feed accessible via RTSP
- Note: if you don't have a camera feed, you can google for public RTSP feeds to use for testing
Enabling Bedrock Model
To use the new Claude 3 Haiku model, it must be enabled in the Amazon Bedrock console. Do this by navigating to the Model access console and clicking Manage model access. Then, select the Claude 3 Haiku model and click Save.
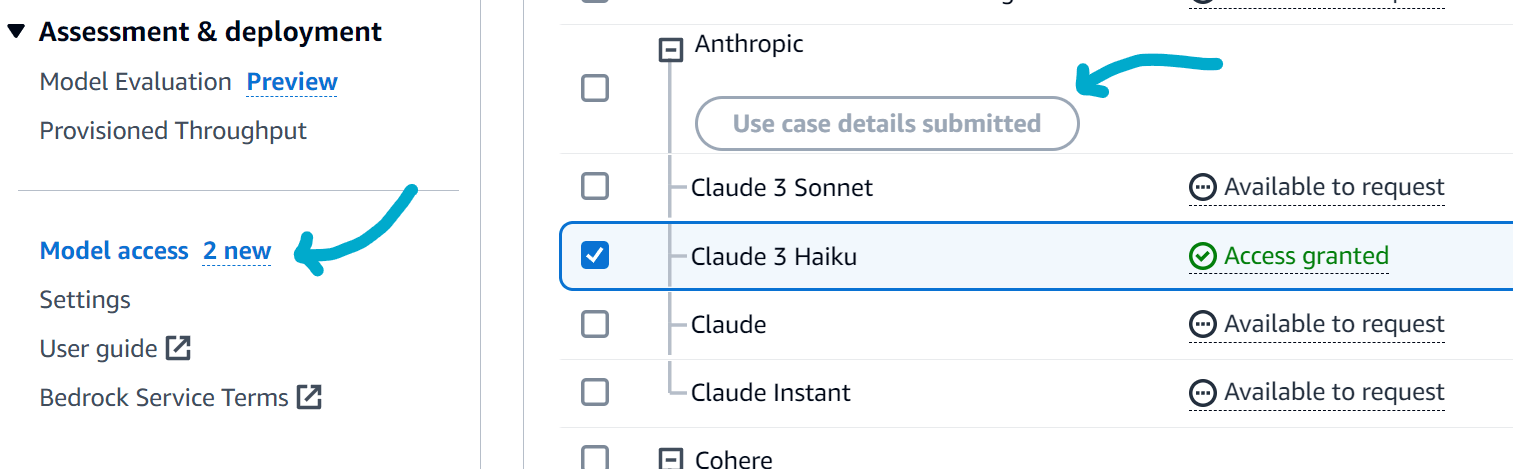
Note: If this is the first time using an Anthropic model, fill in the use case details form. This form is instantly approved and does not require waiting for a response.
Once this step is complete, you might need to wait a few minutes for the model to be available in the Amazon Bedrock console. While waiting, click Providers and select Anthropic to view additional information about the model.
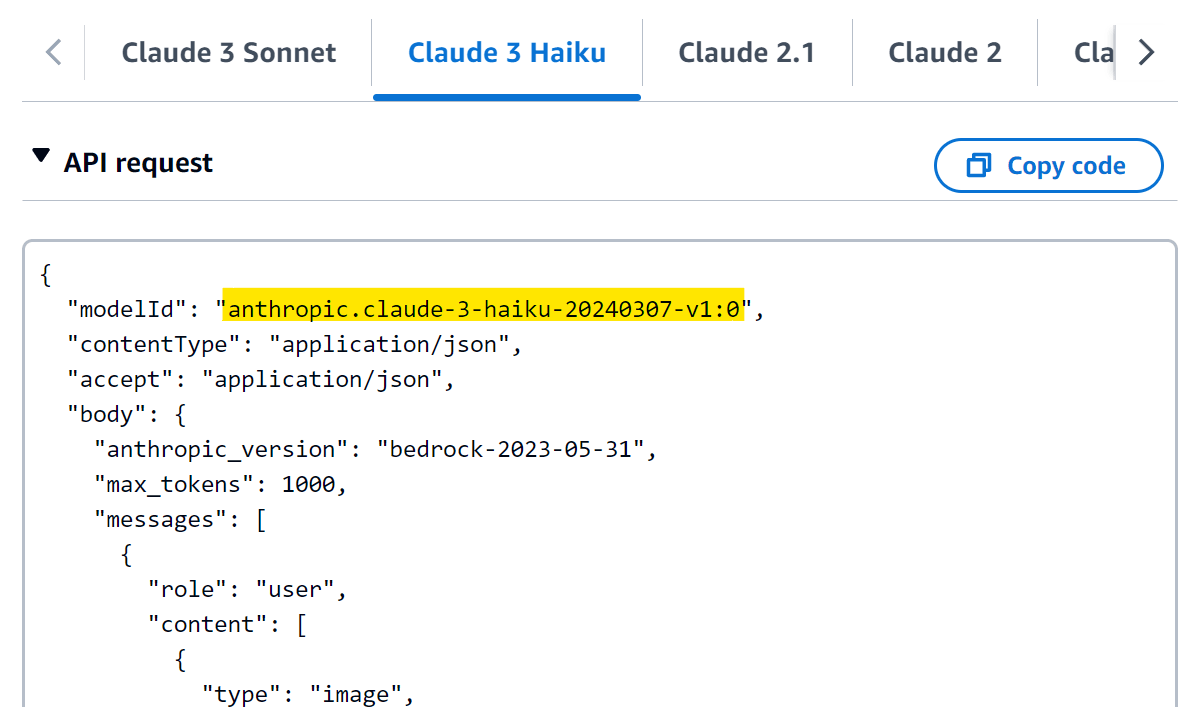
Clicking on the Claude 3 Haiku model will show additional documentation about interacting with the model's API. Importantly, it provides the modelId, which will be used in the next step. In this case, it is anthropic.claude-3-haiku-20240307-v1:0; however, this may change in the future, and you should always use the modelId provided in the Amazon Bedrock console.
Using the Model
Note: You must set up AWS credentials on your machine for this to work. If you don't have them set up, you can follow the AWS CLI configuration guide.
# Download the script, make it executable
curl https://gist.githubusercontent.com/t04glovern/291ed85317e43dce02dce158d9ec4642/raw \
> rtsp_claude3_haiku_bedrock.py \
&& chmod +x rtsp_claude3_haiku_bedrock.py
# Create a virtual env (optional)
python3 -m venv .venv
source .venv/bin/activate
# Install the dependencies
pip3 install boto3==1.34.62 opencv-python-headless==4.9.0.80Now, you can run the script with the following command to see the model in action:
./rtsp_claude3_haiku_bedrock.py \
--url "rtsp://test:password@192.168.188.60:554//h264Preview_01_sub"Alternatively, you can also override the default prompt by using the --prompt flag:
./rtsp_claude3_haiku_bedrock.py \
--url "rtsp://test:password@192.168.188.60:554//h264Preview_01_sub"
--prompt "You are the Eye of Sauron overlooking my empire (house in a residential street). Your job is to look upon the land and tell me about anything suspicious you see. Do not comment on typical things you see in a normal suburban street or driveway. Your job is only to alert me to truly atypical actions."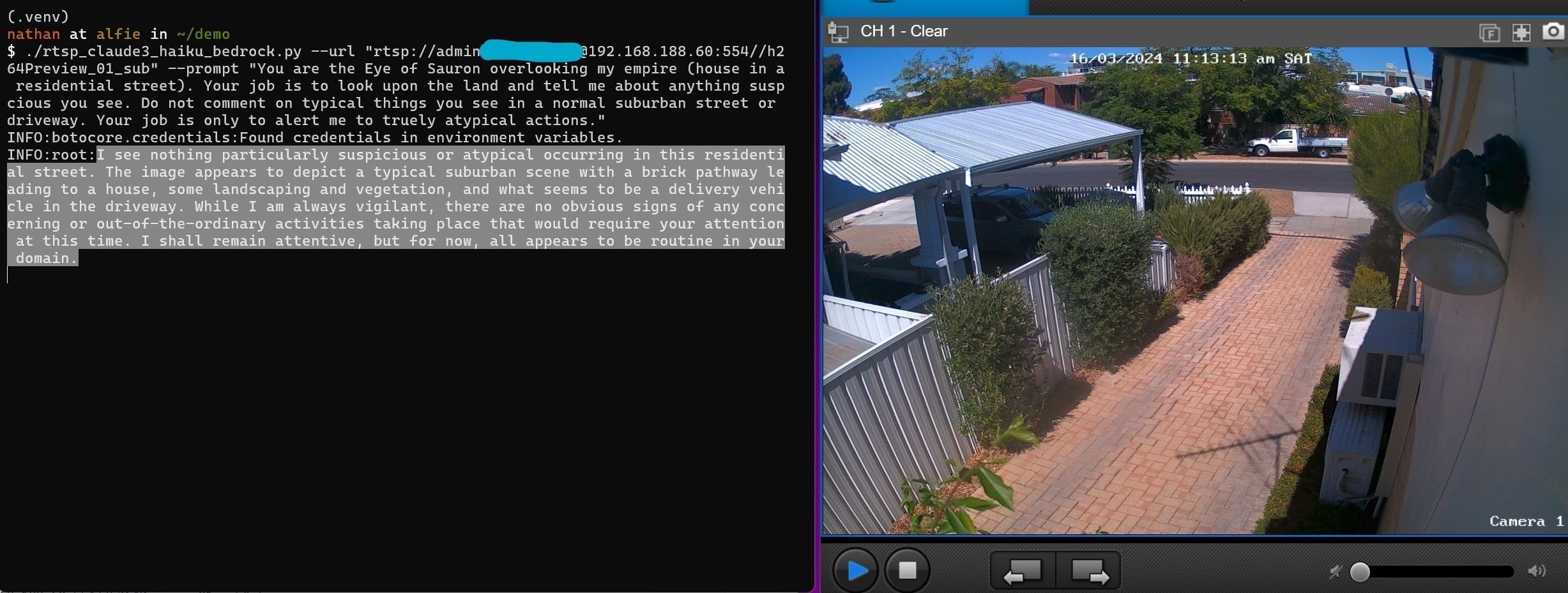
Sending multiple frames
This is cool; however, the script only takes a single frame from the video feed and sends it to the model. This is not very useful for a security camera system. Instead, we want to send a series of frames to the model and only alert us when something interesting happens.
The content array we have sent to the model is a list of data types (image and text). According to the Vision documentation from Anthropic, we can send up to 20 images in a single request.
prompt_config = {
...
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_string,
},
},
{
"type": "text",
"text": custom_prompt,
},
...
}This can be achieved by modifying the script to take a list of frames and send them to the model.
def call_claude_haiku(base64_strings, custom_prompt):
image_blocks = [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_string,
},
} for base64_string in base64_strings
]
prompt_config = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"messages": [
{
"role": "user",
"content": image_blocks + [{"type": "text", "text": custom_prompt}],
}
],
}
...Testing this out, we can see that the model can now process multiple frames and provide a response.

Conclusion
This was a fun experiment, and I don't think it provides anything practically useful. However, it does prove that the tech influencer takes from last year might not be as far-fetched as we thought.
I'm still not sold, but I had fun 😊
If you have any questions or feedback, please feel free to reach out to me on Twitter or LinkedIn.