S3 Batching - Drastically Simplifying Your IoT Architecture


Introduction
Over the past few years, I've been lucky enough to work on many IoT projects for various clients. And while each project has been unique, one unsung hero is always present in every single one of them: S3.
What I find most interesting is that S3 is usually (one of) the final destinations for data, but it is rarely the first.
The rationales that are usually given are:
- "We want real-time data, so we need to use Kinesis Data Streams, but we also want to store the data cheaply long-term, so we need to use S3."
- "We make all our decisions at the edge, but we still want to store the data in S3 for auditing purposes."
- "We don't know what we want to do with the data yet, so we'll just store it in S3 and figure it out later."
While these are all valid reasons, they could ignore a much simpler solution - use S3 from the start. I set out to see if this design would be feasible and where the limitations would be. Are 99% of IoT projects over-engineered? Let's find out.
What does going to S3 first look like?
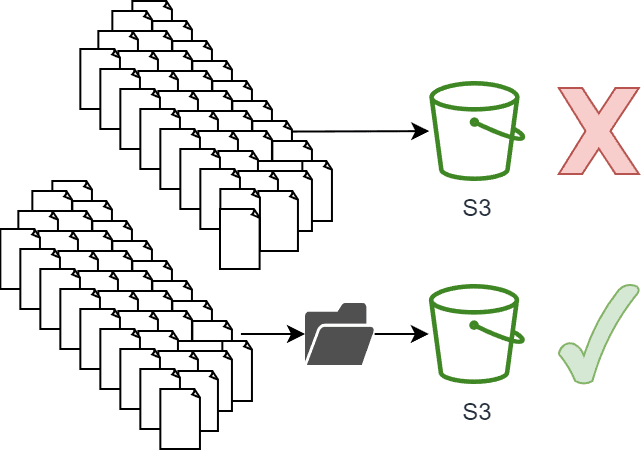
So, what does this look like in practice? Well, S3 isn't like IoT Core or Kinesis Data Streams. You wouldn't want to send each message to S3 individually, as this would be expensive and inefficient.
Instead, you would want to pack the messages and send them to S3 in batches.
How big of a difference does this make? Well, let's say you have 40 sensors that send 100 messages (166.25 bytes) per second - that's 4,000 messages per second that you would need to send to S3. Below is a comparison of costs comparing different batch sizes alongside services that you would typically use for IoT data ingestion.
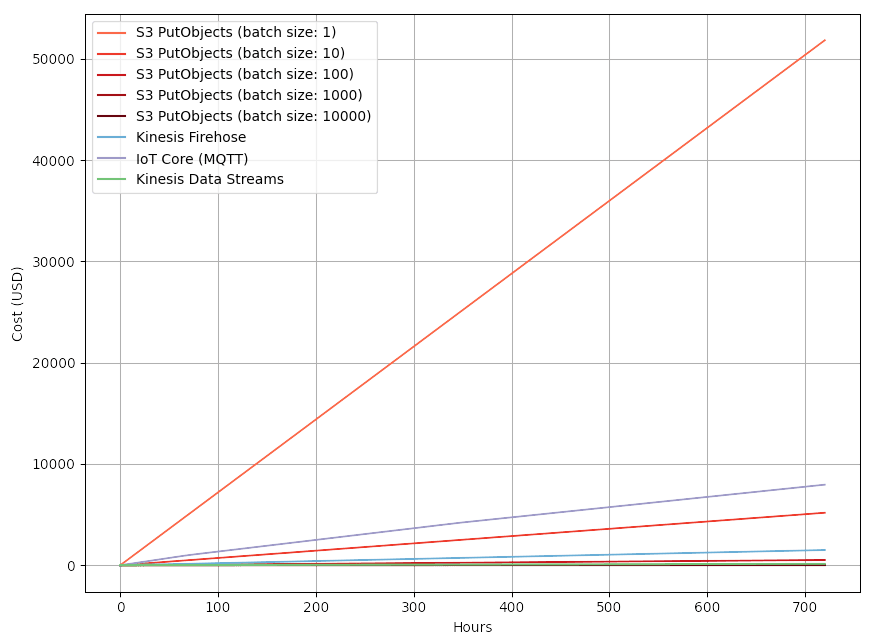
It's pretty clear that, at the very least, S3 should not be used without batching (~$52,000 per month). The second most expensive option is IoT Core (MQTT), which is ~$7,500 monthly. This cost seems high, but it is important to remember that IoT Core was never sold as the best option for the scenario where we are just looking at ingesting bulk data.
It is more likely that you would use Kinesis Firehose, and to get an easier-to-view comparison, I've excluded the S3 single object and IoT Core (MQTT) options from the graph below.
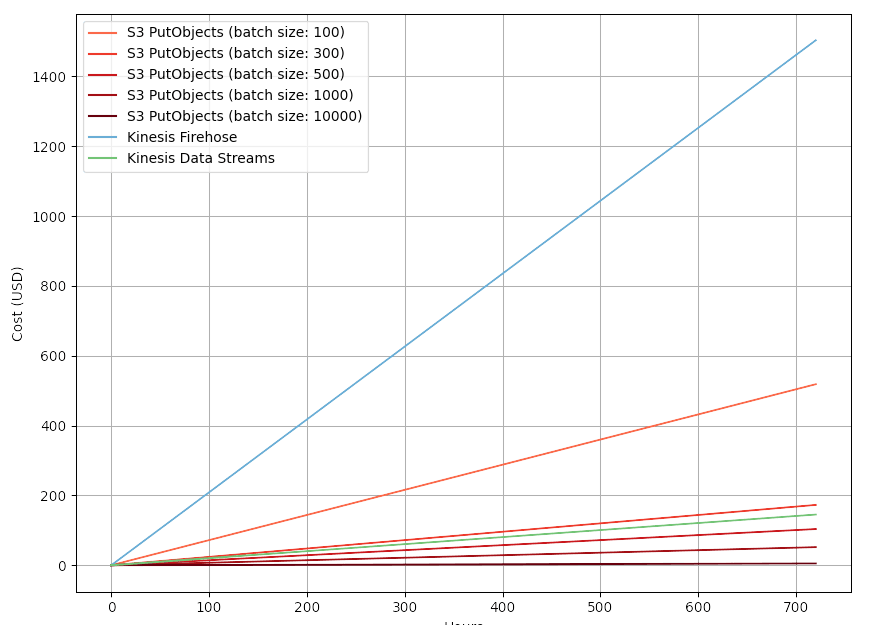
Kinesis Firehose is ~$1,500 per month, but again, this cost has a caveat: Firehose bills at a 5kb minimum per record. If you send a 1kb message, you will still be billed for 5kb.
Firehose is likely to be the option most companies land on though, not because of cost but purely because it is simple to set up and use - compared to Kinesis Data Streams, which is far more complex and requires you to use the native producer library in Java. If you can get past the complexity of Kinesis Data Streams, you can get the cost down to ~$180 per month.
This leaves us with the S3 batching option, which is anywhere:
- As high as $500 per month (if you batch twice a second - 500 records per batch)
- As low as $5 per month (if you batch once every 2.5 seconds - 10,000 records per batch)
It's important to note that the cost of S3 batching is not fixed, and you can adjust the batch size to suit your needs. This is similar to how you can adjust the batch size of Kinesis Data Streams to suit your needs.
How do we batch messages?
So we've established that S3 batching is the cheapest option, but how do we batch the messages?
For this guide, I will be using AWS Greengrass and a custom Greengrass component that I've written for this very purpose.
It should be noted that you don't need to use Greengrass to batch messages. You could use any technology you want, as long as the pattern follows: "Receive messages -> Bundling and compressing messages -> Send to S3".
What's important is that messages are batched into a format that downstream consumers can easily read. Parquet is a popular format for this, as it is columnar and compresses well - in fact, a similar AWS prescriptive guide on this very architecture used it. However, I'm a big fan of simple line-delimited JSON, compressed to GZIP - as it's a globally understood format and is easy to work with.
If you are planning on using a different format, you should check the Supported SerDes and data formats guide for Athena, as it will make your life easier when it comes to querying the data.
Greengrass S3 Ingestor component
I won't go into too much detail about how to set up AWS Greengrass, as there are plenty of guides out there already - in fact, I've written many myself: https://devopstar.com/category/blog/greengrass/. Instead, I'll focus on how I wrote the custom Greengrass component - so that if you wanted to build something similar for your use case, you could.
The architecture of the component at a high level looks like this:
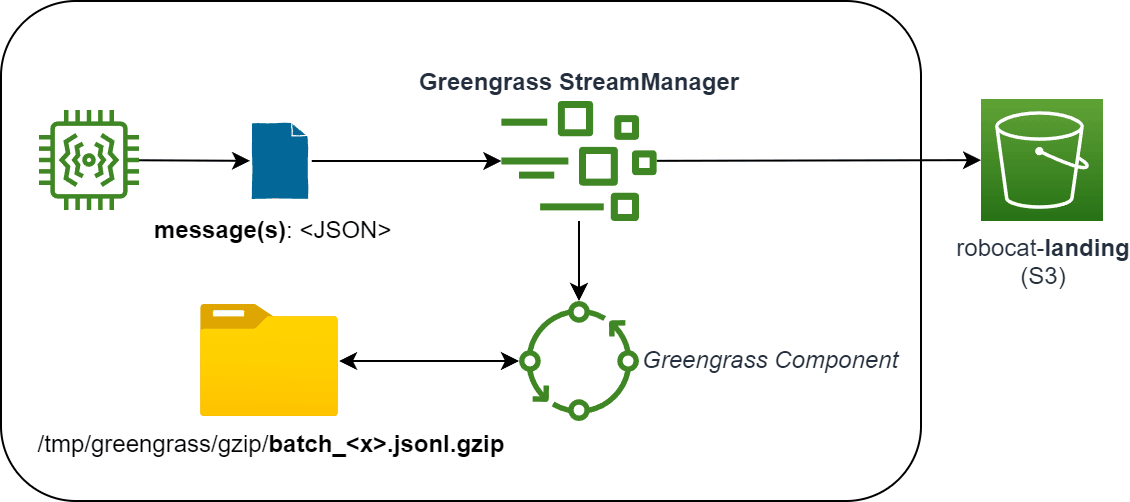
I heavily leveraged the Stream Manager component for Greengrass, as it provides a lot of the functionality that I needed out of the box, such as:
- Buffering - The component can store messages locally until network connectivity is restored.
- Export Configuration - Built-in task engine that can be used to both send data to S3 and then return a status message. It runs asynchronously, so it doesn't prevent the component from receiving new messages.
- Basic API - Connect to the stream manager API from most popular languages.
Let's break down the component into its parts and understand how it works.
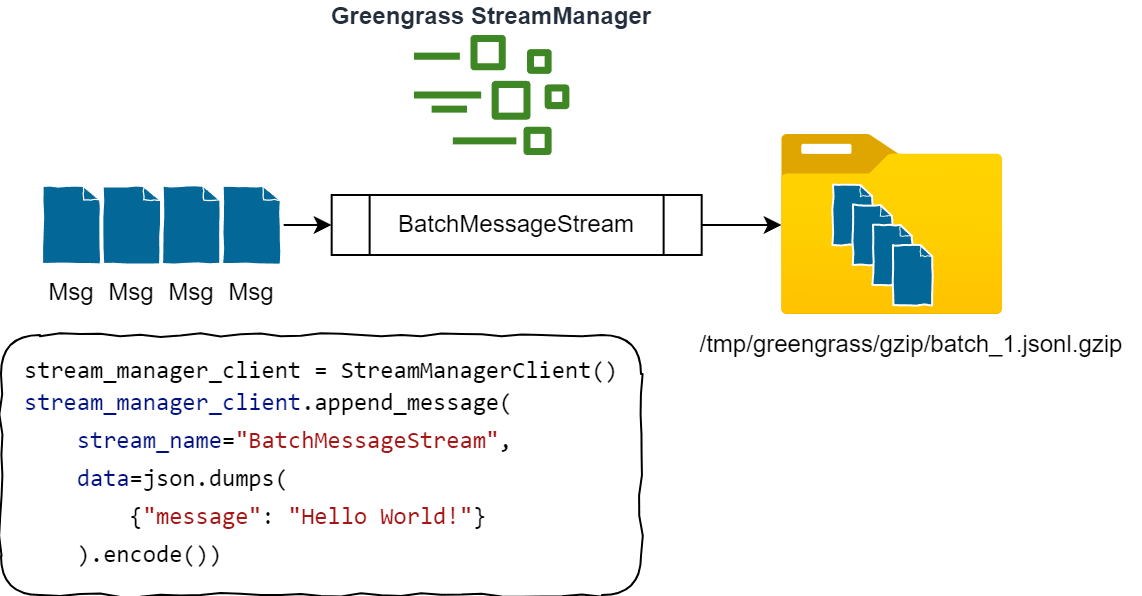
As messages are sent by the devices in the field, they are received by the Stream Manager component. The component then batches the messages together until it reaches the configured batch size (by default, 200 messages). Once the batch size is reached, the messages are compressed into a single GZIP file and placed into the configured output directory (by default, /tmp/greengrass/gzip).
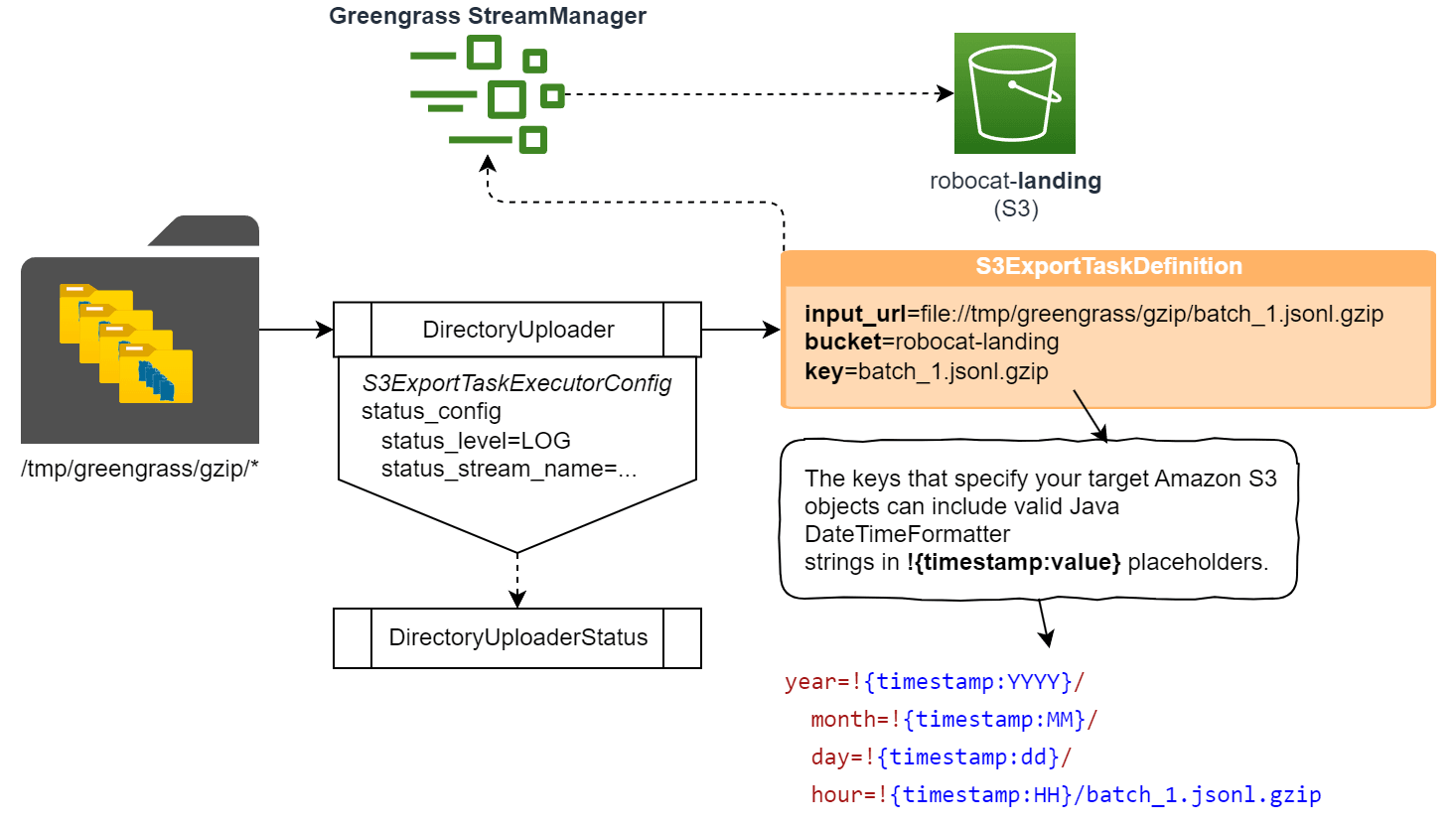
The component then monitors the output directory for new files. Once a new file is detected, a Stream Manager export configuration is created. An export configuration can be thought of as a task run asynchronously by the Stream Manager component and responsible for sending the file to S3.
They offer some powerful features like the support for Java DateTimeFormatter patterns so that batched data can be sent in a partitioned format. By default, the component will use the following pattern:
year=!{{timestamp:YYYY}}/month=!{{timestamp:MM}}/day=!{{timestamp:dd}}/hour=!{{timestamp:HH}}This will result in the following S3 key:
year=2024/month=01/day=27/hour=18/batch_num.jsonl.gzFinally, the component will wait for the export configuration to complete. Once completed, the file is deleted from the output directory, and the component will start monitoring for new files again.
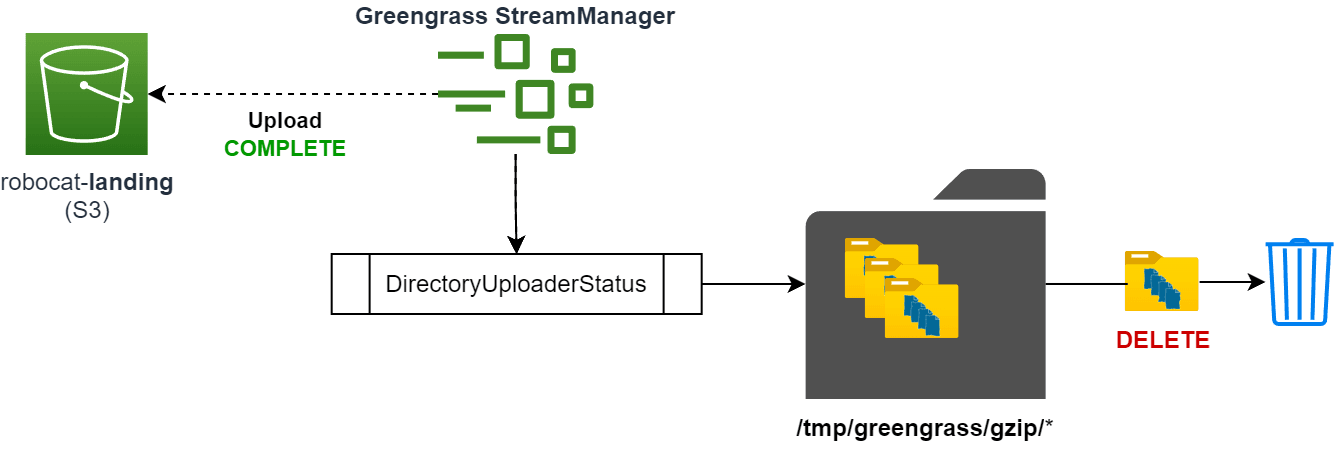
All of this is done in a single component and asynchronously. This means that the component can continue receiving messages while sending data to S3.
Using the component
There are two ways to use the component:
Deploying the component yourself
If you want to deploy the component yourself into your AWS account, you can follow the instructions in the GitHub repository
The TL;DR is:
git clone https://github.com/t04glovern/aws-greengrass-s3-ingestor.git
cd aws-greengrass-s3-ingestor
pip3 install -r requirements-dev.txt
# Build component
gdk component build
gdk test-e2e build
# Run integration tests [optional]
export AWS_REGION=ap-southeast-2
gdk test-e2e run
# Publish component
gdk component publishOnce deployed, you can confirm the component is available by heading to the AWS IoT Greengrass console and checking the components section.
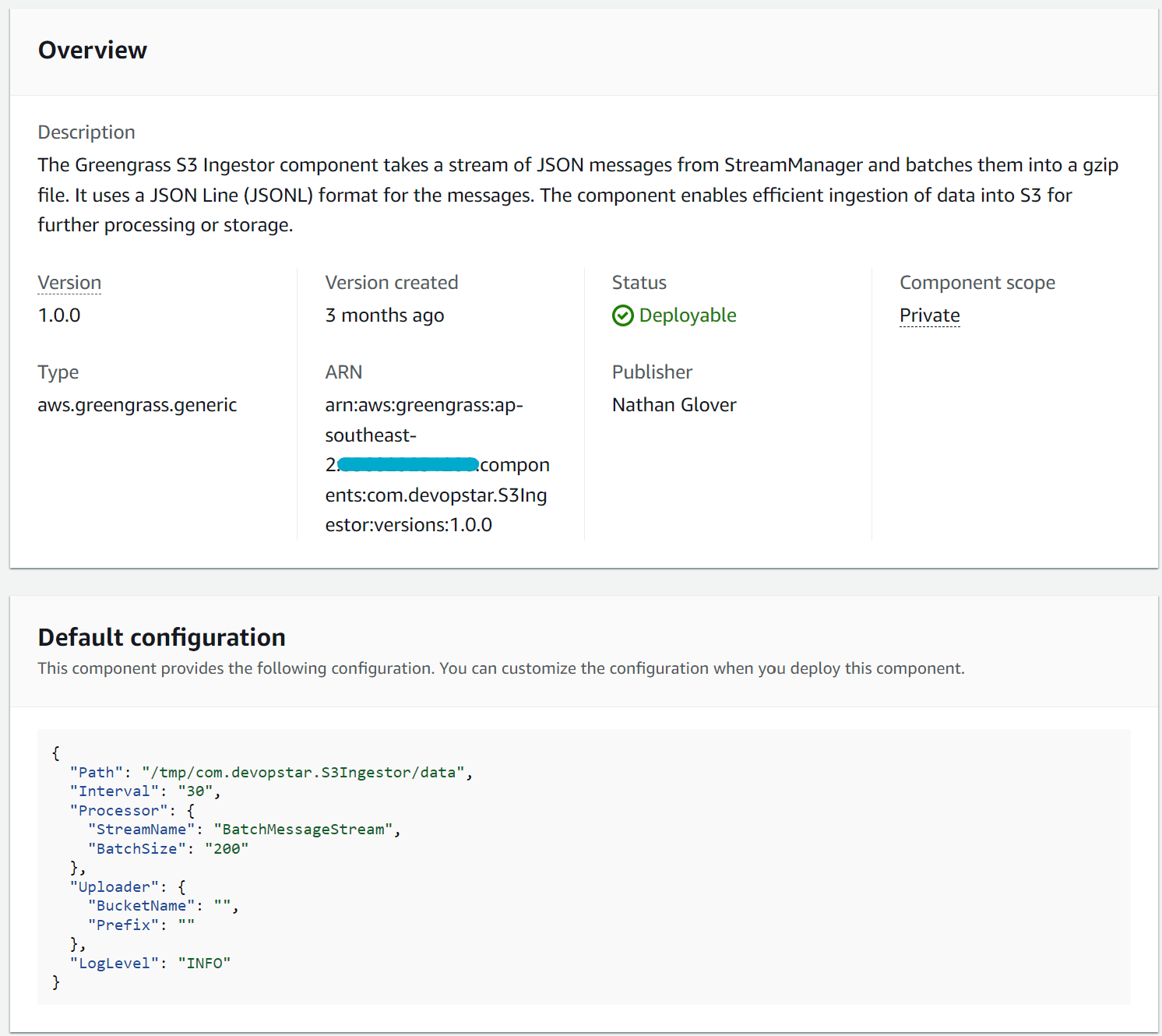
You can then create a deployment that includes the component and provide configuration based on your needs. The only parameter that is required is the S3 bucket name where data will be sent; however, the following parameters can also be configured:
ComponentConfiguration:
DefaultConfiguration:
Path: "/tmp/com.devopstar.S3Ingestor/data"
Interval: "30"
Processor:
StreamName: "BatchMessageStream"
BatchSize: "200"
Uploader:
BucketName: "my-bucket"
Prefix: "devices"
LogLevel: "INFO"More information on each parameter can be found in the GitHub repository. An example of how I configured my deployment can also be found in the GitHub repository.
Using the Publisher-supported version
If you are feeling adventurous, maybe you could be among the first to use the Publisher-supported component version! If you check out the Publisher-supported components page you should see my Greengrass S3 Ingestor listed.
Publisher-supported components are in preview release right now, and if you do think you have a use case for my component, I would genuinely love to work with you to get it deployed and working. You can use the contact details on the page linked above and request to use the component.
What about querying the data?
When the data lands in S3, is it partitioned by year, month, day and hour. This makes it easy to query the data using Athena or another query engine to get insights into the data quickly.
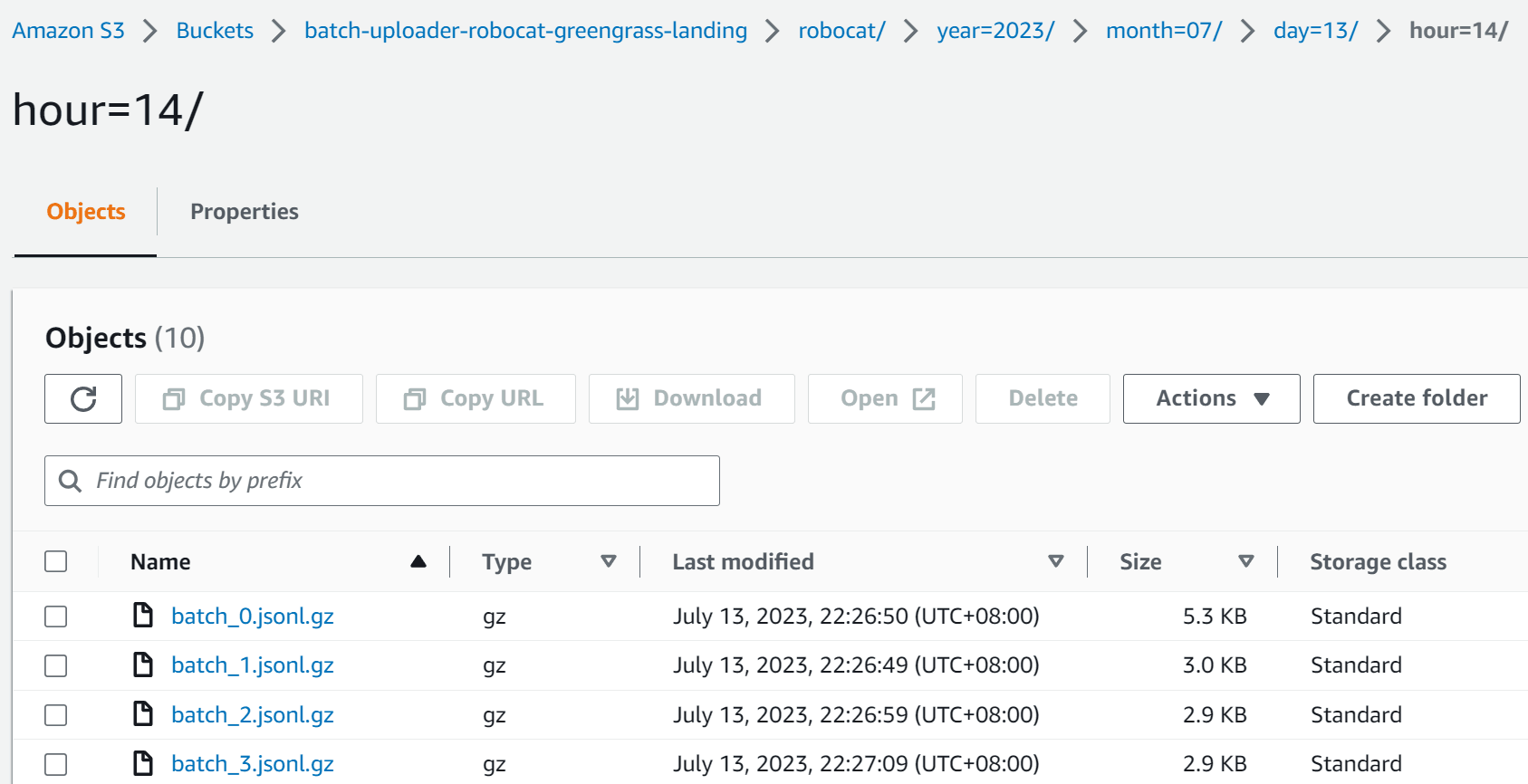
Below is the SQL for creating a table in Athena that can be used to query the data:
CREATE EXTERNAL TABLE IF NOT EXISTS greengrass_data (
`id` string,
`timestamp` timestamp,
`speed` int,
`temperature` float,
`location` struct < lat: float,
lng: float >
)
PARTITIONED BY (
year int,
month int,
day int,
hour int
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
WITH SERDEPROPERTIES ( "timestamp.formats"="yyyy-MM-dd'T'HH:mm:ss.SSSSSSZZ" )
LOCATION 's3://batch-uploader-robocat-greengrass-landing/robocat/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.year.type" = "integer",
"projection.year.range" = "2023,2033",
"projection.month.type" = "integer",
"projection.month.range" = "1,12",
"projection.month.digits" = "2",
"projection.day.type" = "integer",
"projection.day.range" = "1,31",
"projection.day.digits" = "2",
"projection.hour.type" = "integer",
"projection.hour.range" = "0,23",
"projection.hour.digits" = "2",
"storage.location.template" = "s3://batch-uploader-robocat-greengrass-landing/robocat/year=${year}/month=${month}/day=${day}/hour=${hour}"
);Then, we can query the data in its raw form:
SELECT *
FROM "greengrass_data"
WHERE year = 2023
AND month = 7
AND day = 12
AND hour = 14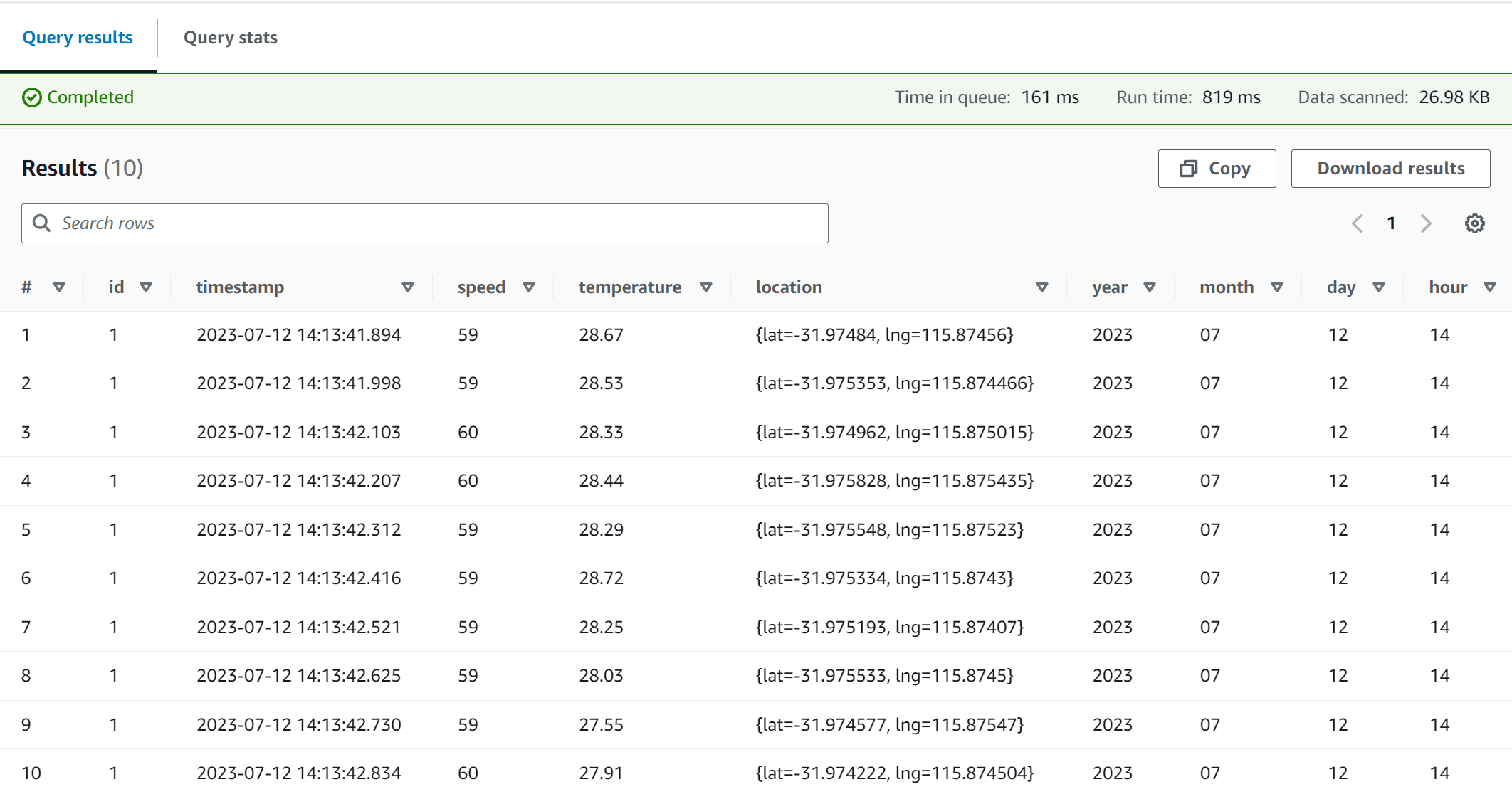
You can also use the following serde2.RegexSerDe format if you don't know the schema of the data
CREATE EXTERNAL TABLE IF NOT EXISTS greengrass_json_data (
jsonstring string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(.*)$",
"projection.enabled" = "true",
"projection.year.type" = "integer",
"projection.year.range" = "2023,2033",
"projection.month.type" = "integer",
"projection.month.range" = "1,12",
"projection.month.digits" = "2",
"projection.day.type" = "integer",
"projection.day.range" = "1,31",
"projection.day.digits" = "2",
"projection.hour.type" = "integer",
"projection.hour.range" = "0,23",
"projection.hour.digits" = "2",
"storage.location.template"="s3://batch-uploader-robocat-greengrass-landing/robocat/year=${year}/month=${month}/day=${day}/hour=${hour}"
) LOCATION 's3://batch-uploader-robocat-greengrass-landing/robocat/';Then, you can query the data using the following.
SELECT * FROM "greengrass_json_data" limit 10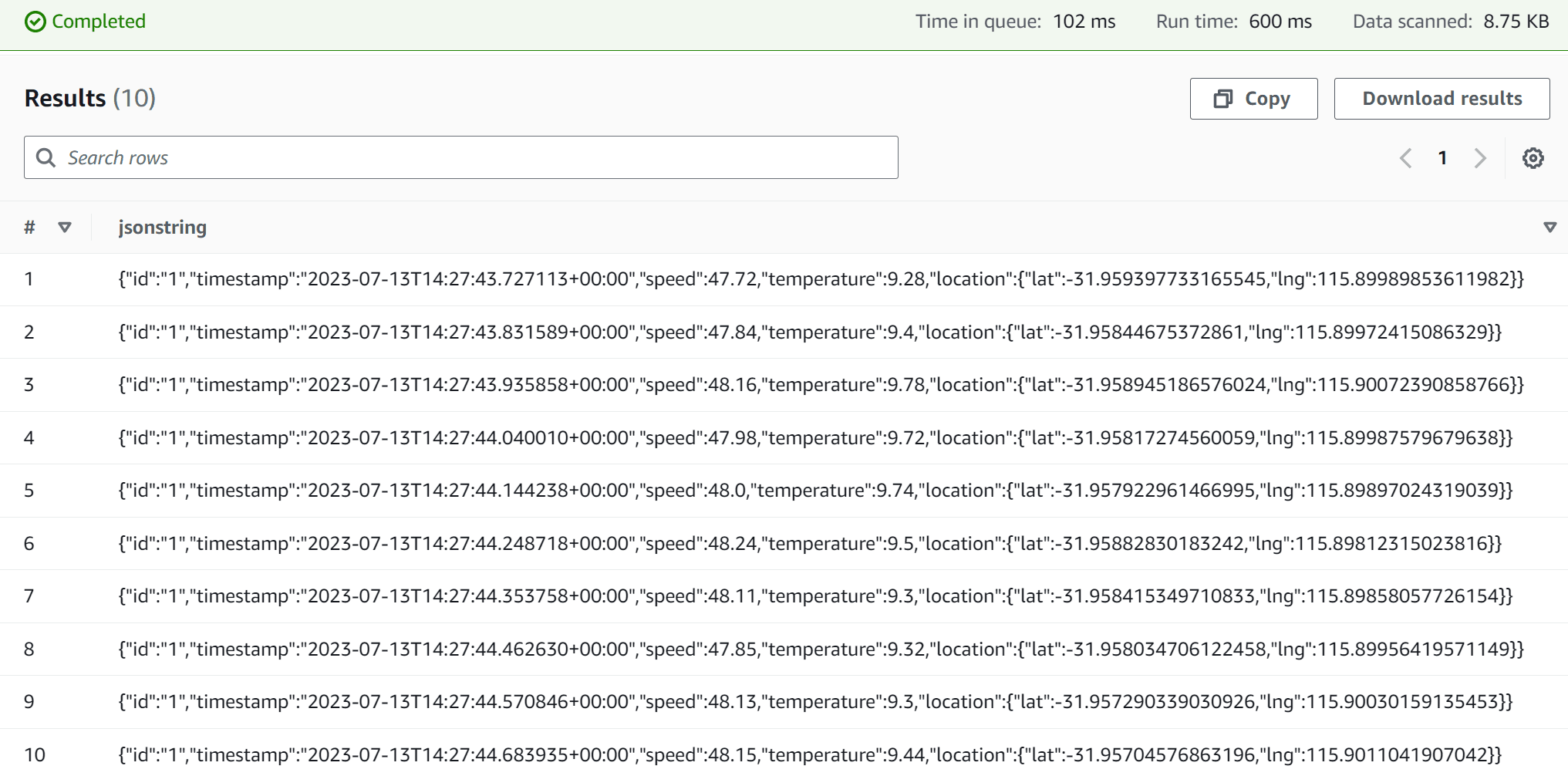
Conclusion
After reading this article, I hope you better understand how batching directly to S3 could simplify your IoT architecture drastically. There's still a place for services like Kinesis Data Streams and IoT Core, but it's important to understand that they are not required to build successful IoT solutions.
S3 batching works particularly well in scenarios where the data consumers and producers work closely together. If the format that data is batched in can be agreed upon and applied as early as possible in the data ingestion pipeline, it significantly reduces both the complexity and cost of the solution.
If you have any questions or feedback, please feel free to reach out to me on Twitter or LinkedIn.