Let's Try - AWS Glue Automatic Compaction for Apache Iceberg

Introduction
Apache Iceberg has been a table format I’ve been diving deeper and deeper into as of late. Specifically, I’ve been using the AWS variant supported by AWS Glue and Amazon Athena. The table format has several powerful features that make it an excellent choice for data lake storage - however, one of those features, compaction, was not supported by AWS Glue until recently.
Before the release of automatic compaction of Apache Iceberg tables in AWS Glue, you had to run a compaction job to optimize your tables manually. This was a bit of a pain, given it was a manual query you had to run against the table - This query had a timeout as well, and you would receive the dreaded ICEBERG_OPTIMIZE_MORE_RUNS_NEEDED error after a timeout. This meant you had to run the query again and again and again until it was finally completed.
In this post, we’ll look at how to use the new automatic compaction feature in AWS Glue and how it can help you optimize your Iceberg tables.
Why Compaction?
The Apache Iceberg documentation has a great section on why compaction is important. In short, compaction is merging small files into larger files. This is important for several reasons, but the most important are performance and cost. Small files are inefficient to read from and can cause performance issues - especially when reading from S3, where you are charged per request.
When you run a compaction job, you merge small files into larger ones. This means you are reducing the number of files that need to be read from and the number of requests that need to be made to S3. This can have a significant impact on performance and cost.
Pre-requisites
To follow along with this post, you must do some minor setup with Athena, S3 and Glue. If you have used Athena before, there’s a good chance you already have this setup (possibly with a different bucket). Feel free to skip this section if you feel confident you have the required setup.
S3
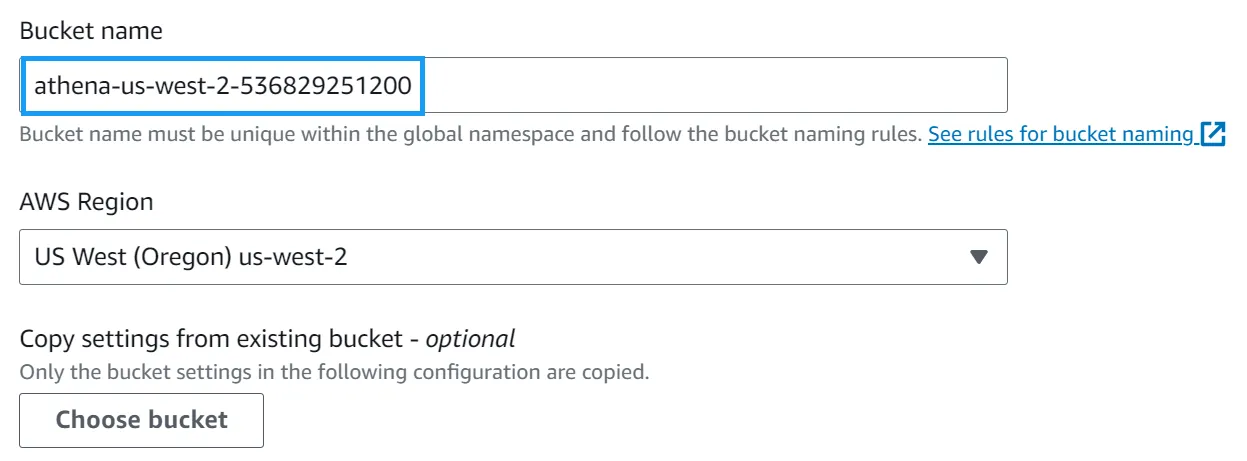
Navigate to the AWS S3 console to start with and create an Athena query bucket
Give the bucket a name such as athena-<region>-<account-id> and click Create bucket. (For example, athena-us-west-2-123456789012.)
Note: for this post, I’ll be using the us-west-2 region as it is one of the regions that supports the new automatic compaction feature.
Athena
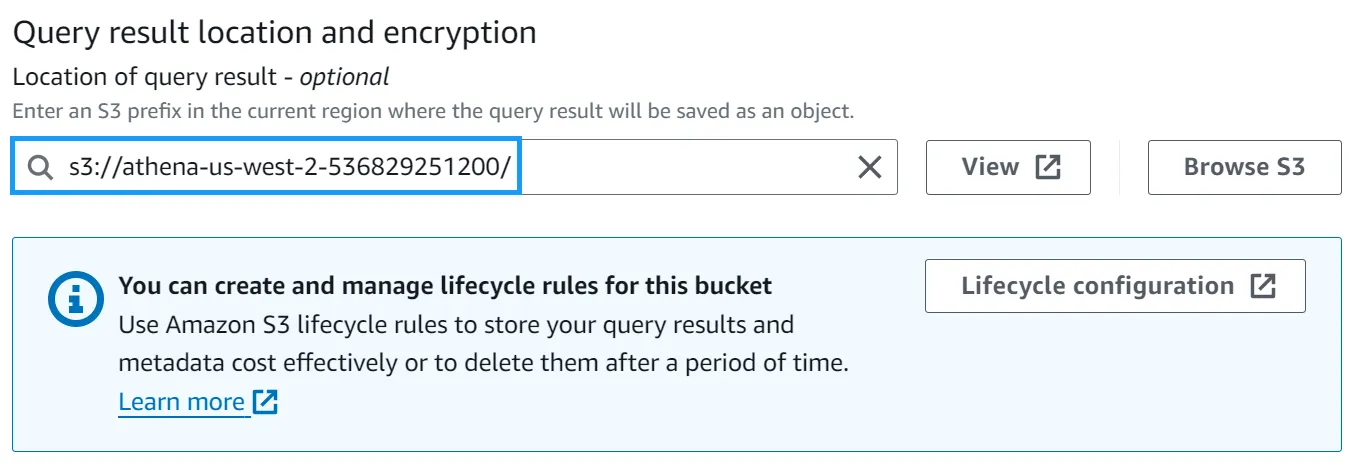
Navigate to the AWS Athena settings console and click Manage under the Query result and encryption settings section.
Change the Location of query results to the bucket you created in the previous step, and click Save.
Glue
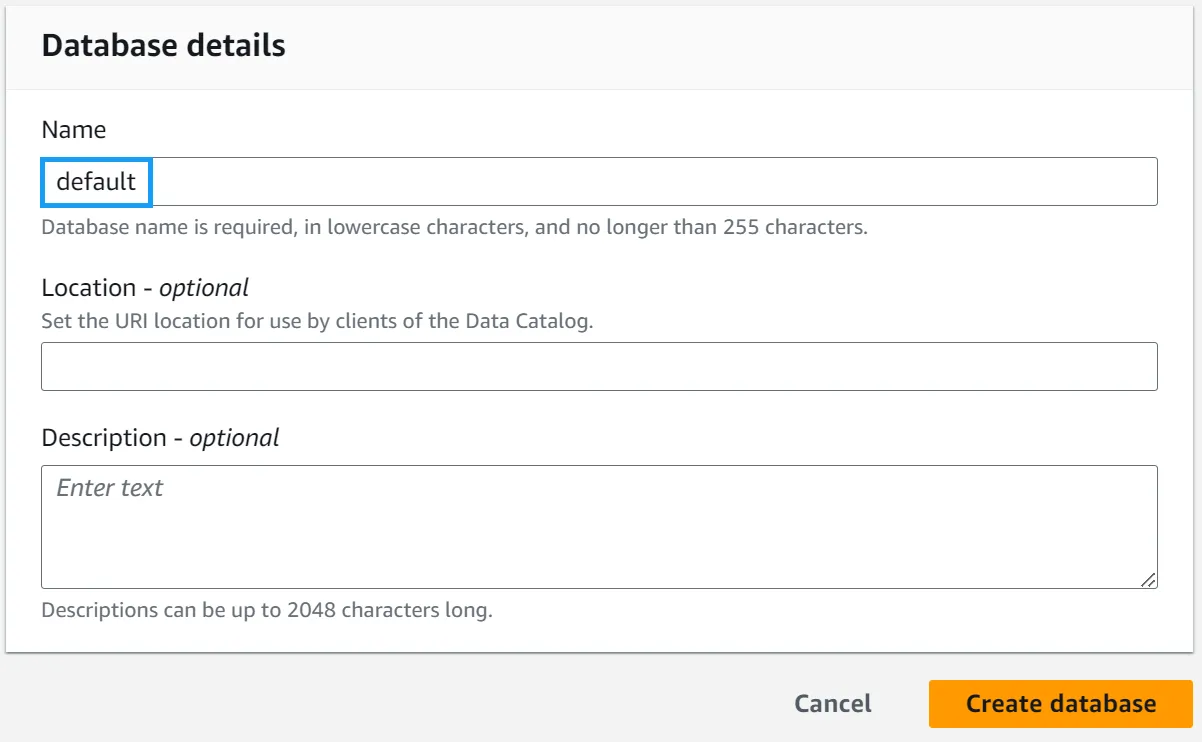
Navigate to the AWS Glue databases console and check to see if you have a database called default. If you do not, create one.
Helper Script
To help demonstrate the new automatic compaction feature, I’ve created a script to do much of the tedious parts of creating an Iceberg table for you. You can find the script here.
At a high level, the script does the following:
- Create an S3 bucket that Iceberg will use to store data and metadata
- Generating 1 million rows of sample data and uploading it to S3
- Create SQL files for:
- Creating an Iceberg table
- Creating a temporary table for loading sample data
- Loading sample data into Iceberg from the temporary table
- Deleting the tables when we’re done
- Creating an IAM role for Glue to use for compaction
Let’s grab the script and run it so you can follow along.
Note: You must set up AWS credentials on your machine for this to work. If you don’t have them set up, you can follow the AWS CLI configuration guide.
# Download the script, make it executable
curl https://gist.githubusercontent.com/t04glovern/04f6f2934353eb1d0fffd487e9b9b6a3/raw \
> lets-try-iceberg.py \
&& chmod +x lets-try-iceberg.py
# Create a virtual env (optional)
python3 -m venv .venv
source .venv/bin/activate
# Install the dependencies
pip3 install boto3
# Run the script
./lets-try-iceberg.py --table lets_try_iceberg_compaction --optimization
Have a look at the output, and you should see something like the following:
# INFO:root:Bucket iceberg-sample-data-477196 does not exist, creating it...
# INFO:root:Uploaded samples.jsonl.gz to s3://iceberg-sample-data-477196/sample-data/samples.jsonl.gz
# INFO:root:Created IAM role lets-try-iceberg-optimization-role
# INFO:root:Created IAM policy lets-try-iceberg-optimization-policy
If you check the directory you ran the script from, you should see several files created:
$ ls -l
# -rw-r--r-- 1 nathan nathan 366 Nov 18 17:26 1-athena-iceberg-create-table.sql
# -rw-r--r-- 1 nathan nathan 403 Nov 18 17:26 2-athena-create-temp-table.sql
# -rw-r--r-- 1 nathan nathan 94 Nov 18 17:26 3-insert-into-iceberg-from-temp-table.sql
# -rw-r--r-- 1 nathan nathan 62 Nov 18 17:26 4-cleanup-temp-table.sql
# -rw-r--r-- 1 nathan nathan 50 Nov 18 17:26 5-cleanup-iceberg-table.sql
The numbered SQL files are the ones we’ll be using to create our Iceberg table and load the sample data into it.
Create & Load the Iceberg Table
Head over to the AWS Athena console and ensure that the default database is selected.
Take the contents of the 1-athena-iceberg-create-table.sql file and paste it into the query editor. Click Run to create the table.
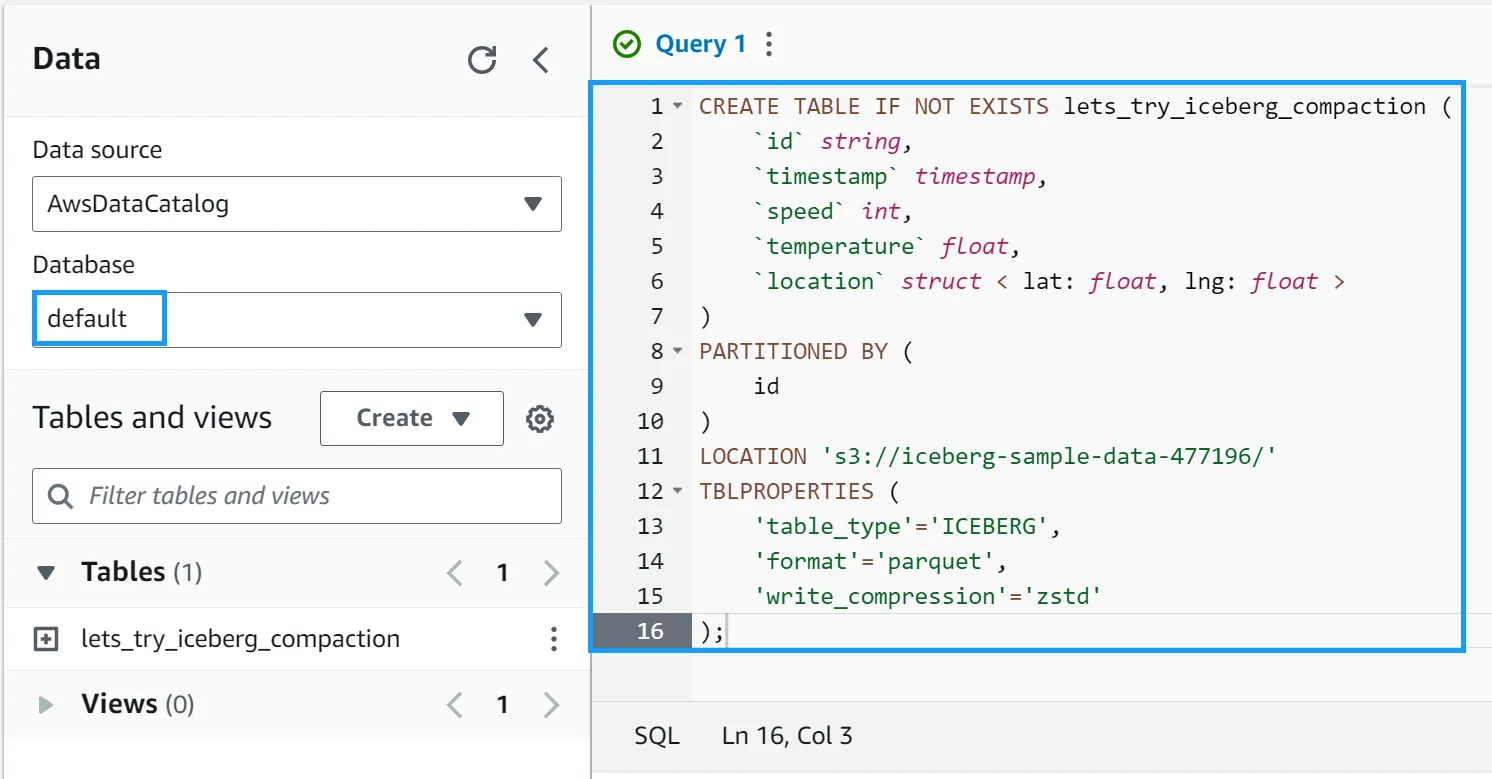
You should see a new table called lets_try_iceberg_compaction under the Tables section of the default database.
We’ll create a temporary table to load the sample data into. Copy the 2-athena-create-temp-table.sql file and paste it into the query editor. Click Run to create the table.
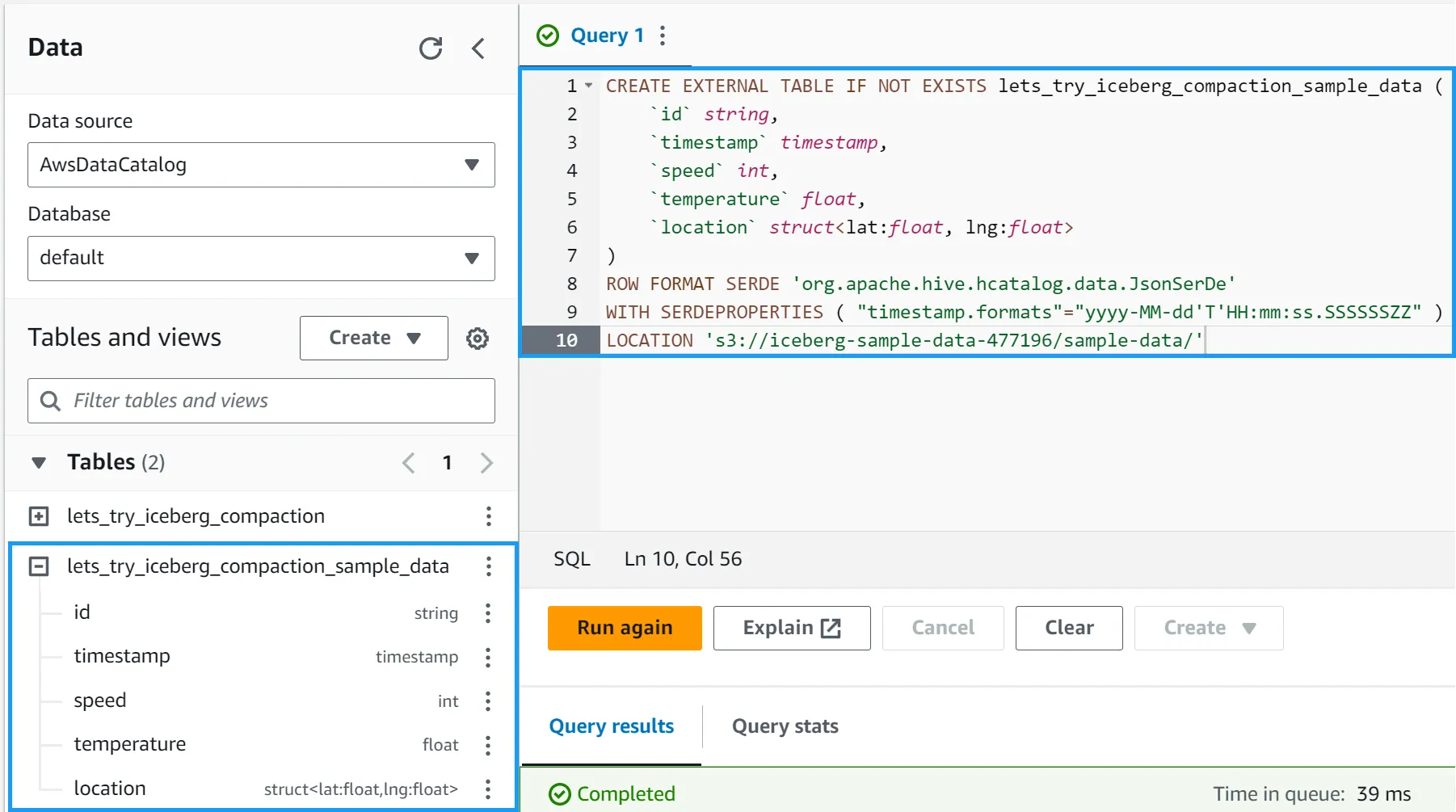
Now, we’ll load the sample data from the temporary table into the Iceberg table. Copy the 3-insert-into-iceberg-from-temp-table.sql file and paste it into the query editor. Click Run to load the data.
Note: This query will take 15-30 seconds to run.
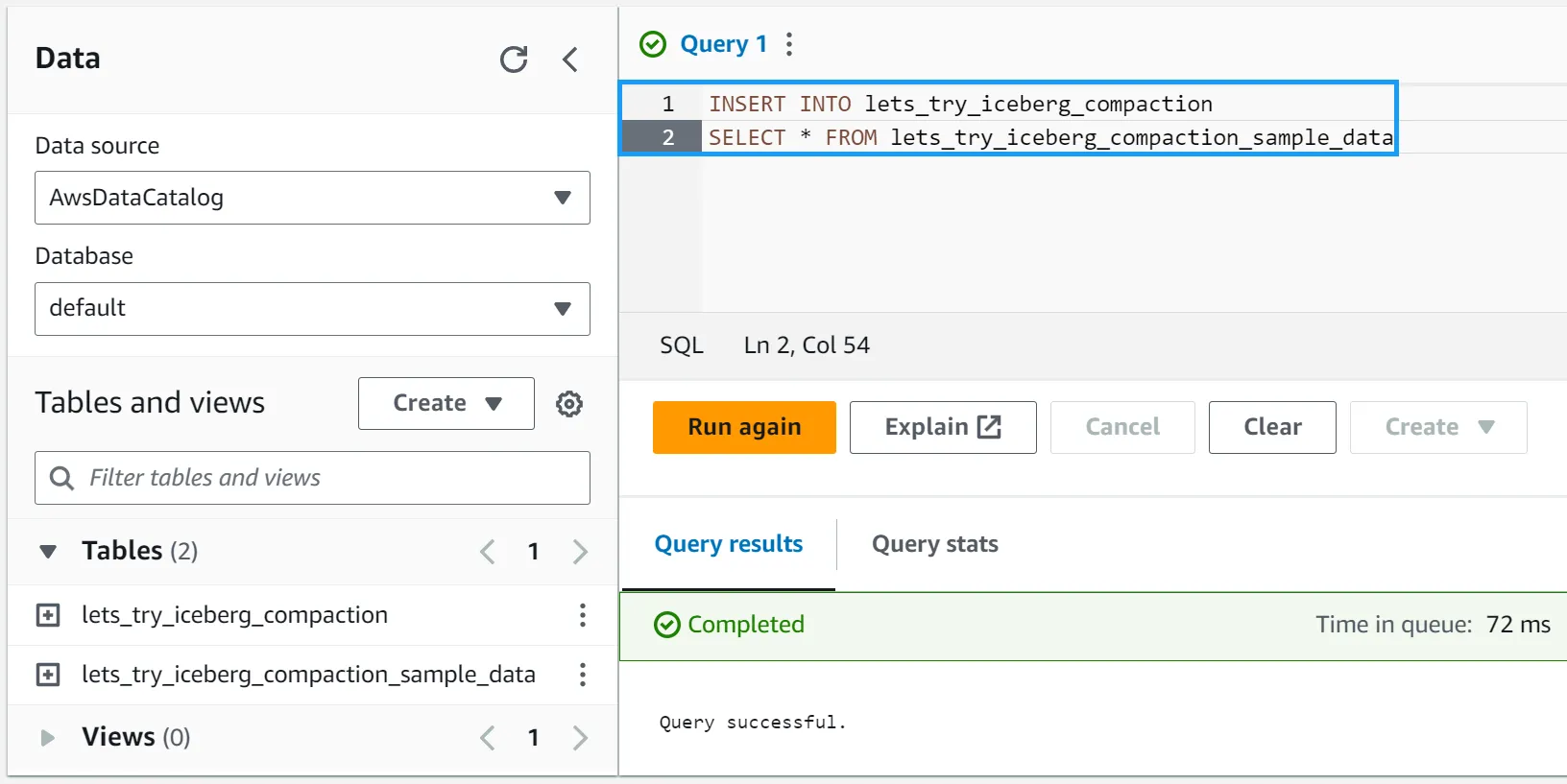
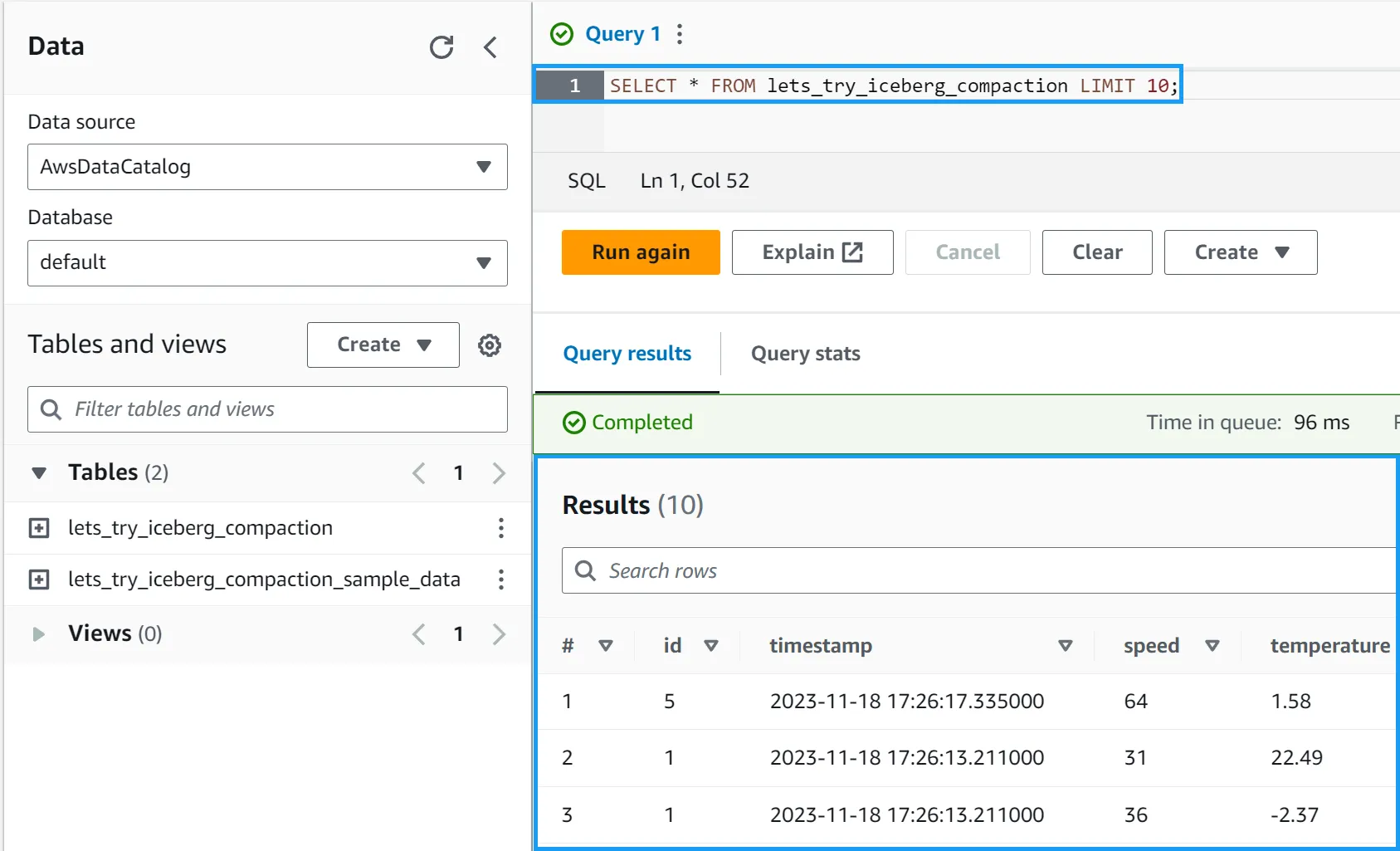
Finally, let’s verify that the data was loaded into the table. Run the following query:
SELECT * FROM lets_try_iceberg_compaction LIMIT 10;
You should see something like the following:
Compaction in Action
Now that we have our Iceberg table created and our sample data loaded into it let’s enable the new automatic compaction feature and see it in action.
Navigate to the AWS Glue tables console and select the lets_try_iceberg_compaction table.
At the bottom of the table details, you should see a tab called Table optimization. Click it, then click Enable compaction.
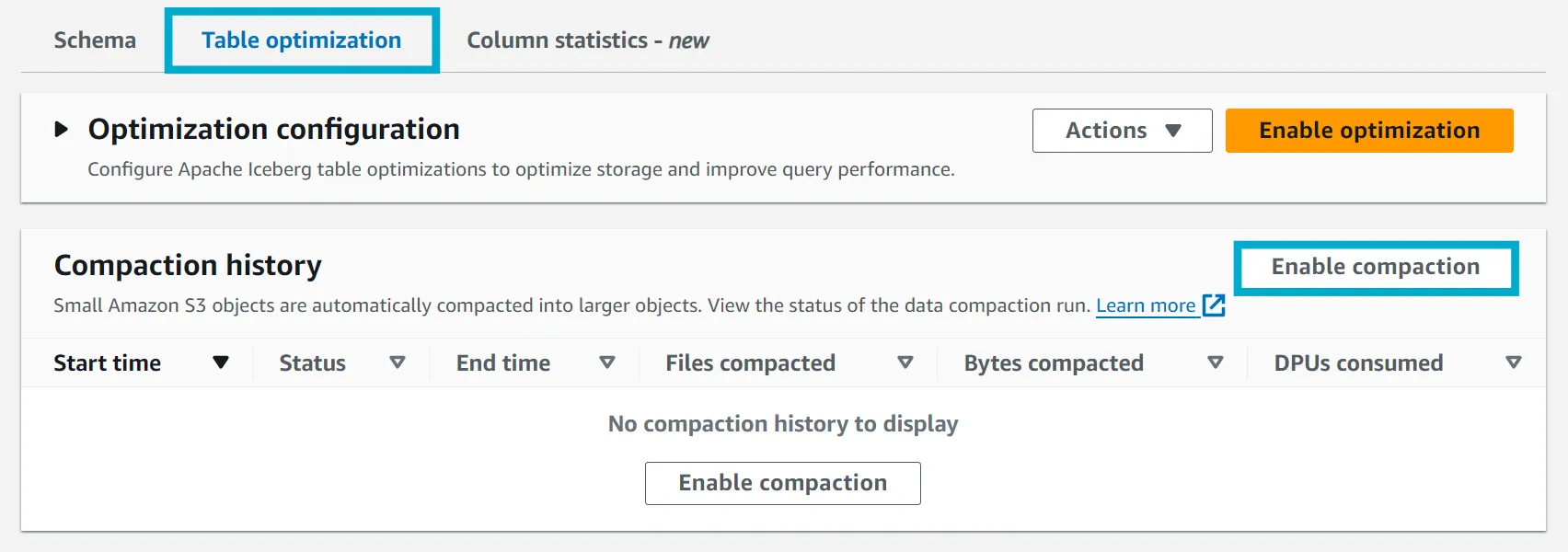
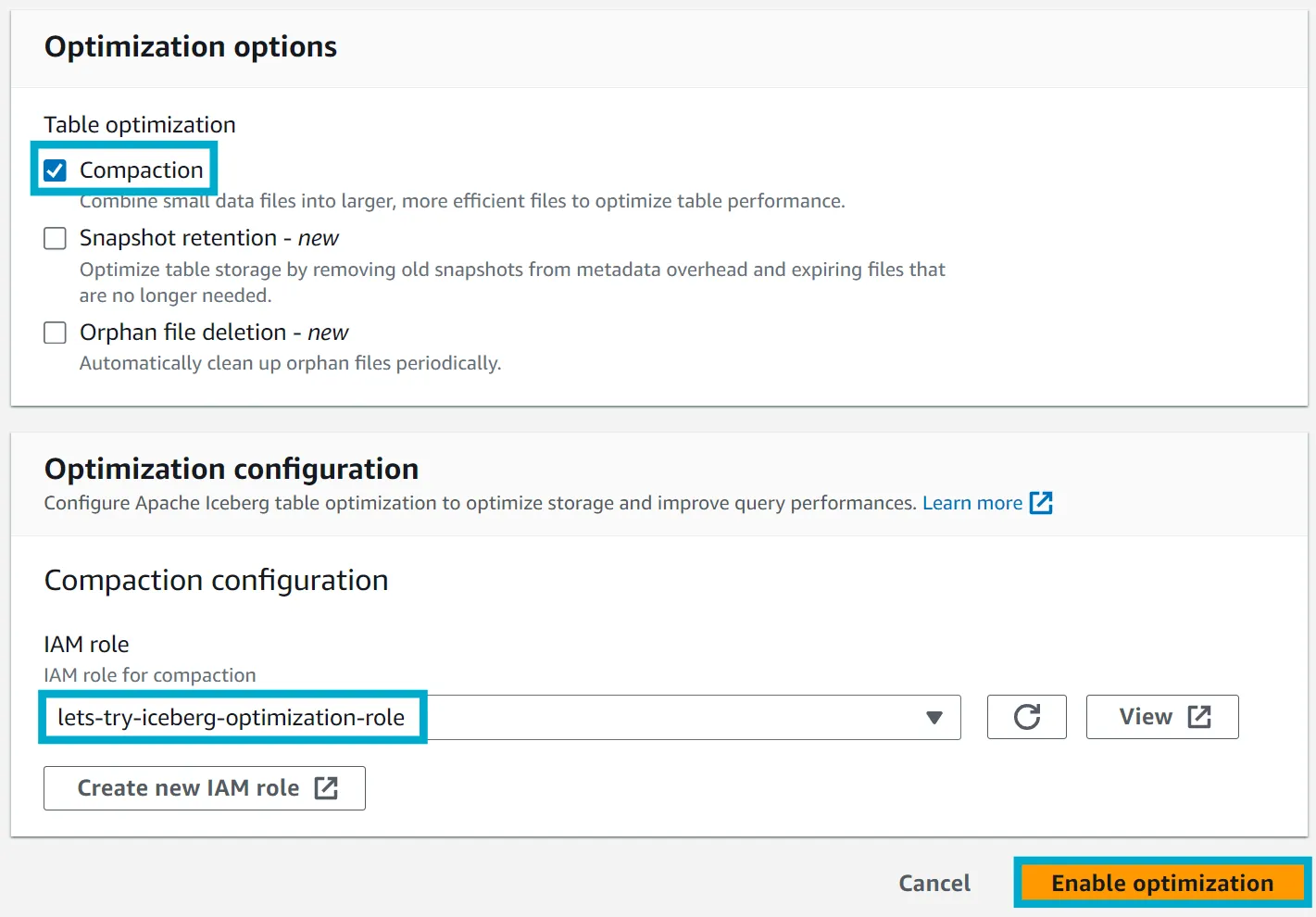
You will be prompted to select a role to use for compaction. Select the role created by the script we ran earlier (lets-try-iceberg-optimization-role), and click Enable compaction.
Navigate back to the AWS Glue tables console and select the lets_try_iceberg_compaction table again. Get a coffee, and when you come back, refresh the page. You should see something like the following:
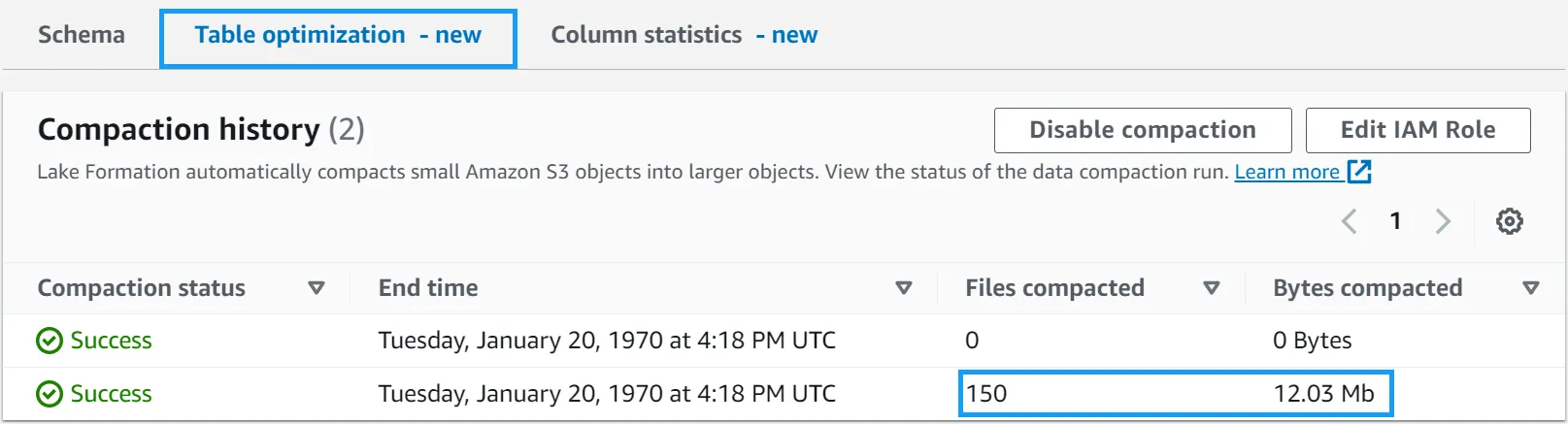
At this point, your table should start automatically compacting based on the rate of changes made. According to the blog post AWS Glue Data Catalog now supports automatic compaction of Apache Iceberg tables this rate of change is based on the following:
As Iceberg tables can have multiple partitions, the service calculates this change rate for each partition and schedules managed jobs to compact the partitions where this rate of change breaches a threshold value.
You can force another compaction job to verify this by navigating back to the Athena console and rerunning the following query:
INSERT INTO lets_try_iceberg_compaction
SELECT * FROM lets_try_iceberg_compaction_sample_data
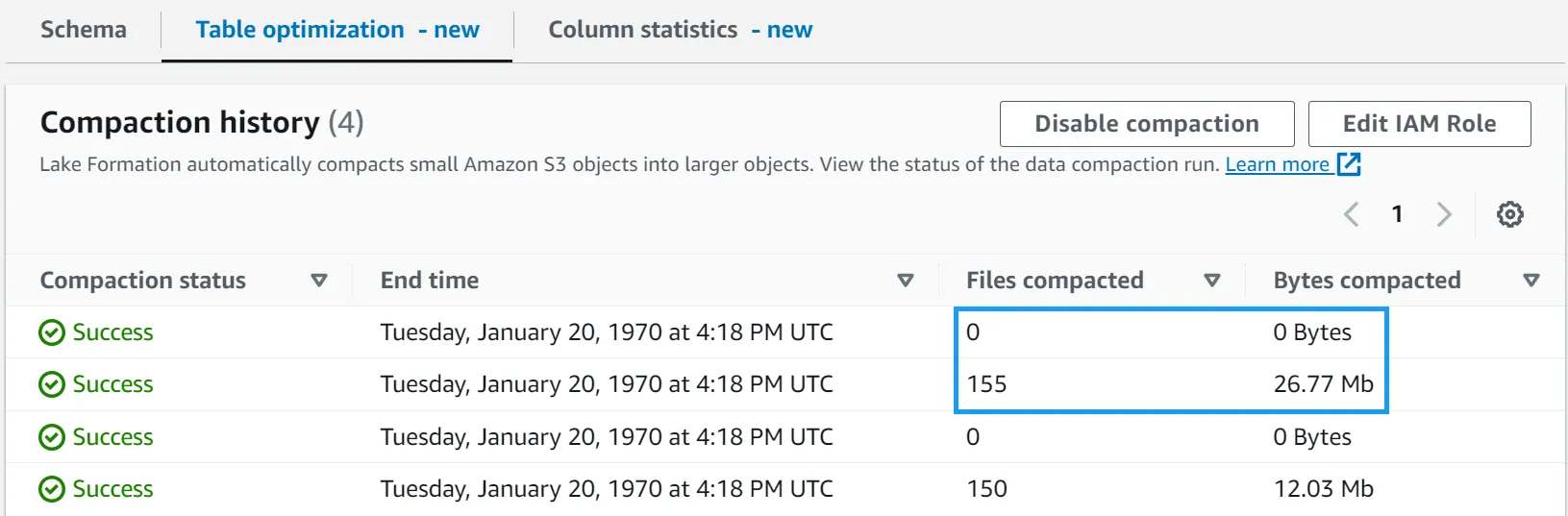
NOTE - Update 05/02/2024: In the Data Catalog, the default threshold value to initiate compaction is set to 384 MB whereas in the Iceberg library the threshold for compaction is ~75% of the target file size. This means that triggering a compaction job might need more data to be inserted into the table than you might expect. To quickly force a compaction job, you can insert the source data onto itself using the following query:
-- Run the following a few times to force a compaction job
INSERT INTO lets_try_iceberg_compaction
SELECT * FROM lets_try_iceberg_compaction
This will insert the sample data into the table again, and you should see another compaction job start in the Glue console.
Cleanup
Once you’re done, you can use the 4-cleanup-temp-table.sql and 5-cleanup-iceberg-table.sql files to clean up the temporary and Iceberg tables.
-- 4-cleanup-temp-table.sql
DROP TABLE IF EXISTS lets_try_iceberg_compaction_sample_data;
-- 5-cleanup-iceberg-table.sql
DROP TABLE IF EXISTS lets_try_iceberg_compaction;
Then, navigate to the AWS S3 console and Empty then Delete the bucket that was created by the script.
Finally, navigate to the AWS IAM Roles console and delete the role (lets-try-iceberg-optimization-role) and policy (lets-try-iceberg-optimization-policy) that were created by the script.
Summary
This post looked at the new automatic compaction feature for Apache Iceberg tables in AWS Glue. We saw how to enable it and how it works in action. We also saw how to force a compaction job to run and how to clean up the resources we created.
Something to keep in mind is that this feature’s pricing is based on DPU hours. According to the AWS Glue pricing page:
If you compact Apache Iceberg tables, and the compaction run for 30 minutes and consume 2 DPUs, you will be billed 2 DPUs * 1/2 hour * $0.44/DPU-Hour, which equals $0.44.
This pricing could add up quickly if you have a high rate of change on your tables - before this feature, you would have to manually run the compaction job, which, although tedious, would incur minimal costs under the Athena pricing model. You will likely want to keep this feature in mind when deciding whether or not to enable this feature. An alternative would be to run the compaction job manually, using a pattern similar to how I did automatic VACUUM jobs in my Vacuuming Amazon Athena Iceberg with AWS Step Functions post.
I’m excited to see this feature released and looking forward to seeing what other features are added to the Glue variant of Iceberg in the future.
If you have any questions, comments or feedback, please get in touch with me on Twitter @nathangloverAUS, LinkedIn or leave a comment below!