Escaping from technical debt when it seems impossible

On August 16th, 2019 Selfie2Anime went live to unexpected success. Unfortunately, the code deployed wasn’t anywhere near ready for the load we experienced and some bad decisions were made in the heat of the moment to get everything up and running. 8 months on and we’re dealing with the consequences of those decisions every day.
In this post, I tell the tale of how we came to terms with our problems and learnt to deal with them. I will also give provide some advice about how we might do things differently next time around.
Note that this post was written from the perspective of a small, part-time team; so it might not translate to large scale organizations. However, I would still advocate that most of the recommendations below are at least worth exploring no matter the circumstance.
Context
Before I get into the weeds it will help if you understand what our service is and why we believe we might have been doomed to fail from the get go.
Selfie2Anime uses unsupervised generative networks (UGATIT) to generate anime images from human selfies.

The fundamental premise: An image is uploaded to our service, processed, then sent back to the user. Pretty simple huh? From a distance this might seem like a pretty standard pattern in terms of hosting, the following architecture is probably what comes to your head.
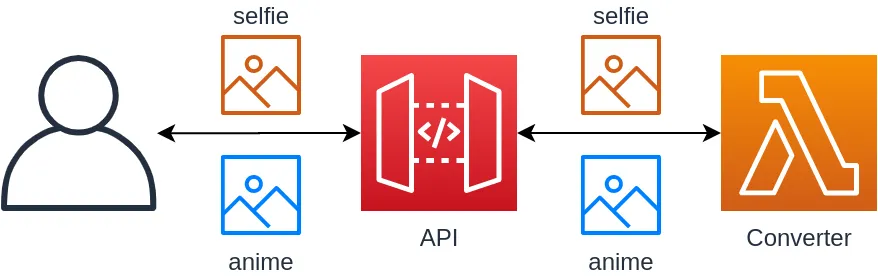
This is more or less exactly what I had in my head too when I prototyped out a very simple concept back at the start of August 2019.
But it wasn’t that simple, and if you want to know more about the problems and how we solved them, I recommend checking out Building Selfie2Anime - Iterating on an Idea.
Problems
With the pleasantries out of the way, let’s dig into the list of things that ended up being major problems for Selfie2Anime.
I’ll fix it later syndrome
When working on software projects, especially when they are experiments or proof of concepts; it’s not uncommon to write quick and dirty code to prove out functionality. Normally the rationale is along the lines of “I know this could be better, but I’ll fix it up later”.
Unsurprisingly this only works if you actually go back and fix it up later.
Here’s a great example of some dud code I wrote when building out the image processing loop. If you’ve worked with Python before, you’ll probably notice a few really bad patterns in the code below.
def runner(args, email, image):
try:
try:
fake_img = gan.test_endpoint(image)
s3 = boto3.client('s3')
file_name = 'outgoing/' + image
image_url = s3.put_object(Body=fake_img, Bucket=bucket, Key=file_name)
email = EmailService()
email.send_email(email, image_url)
except Exception as e:
raise e
except Exception as e:
print('FATAL ERROR')
print(e)
- Single broad
Exceptionbeing caught for all errors - No caching of service clients (email, s3, etc.)
- Errors aren’t particularly useful.
A more useful way to write the above code could have been what is shown below (however even this isn’t necessarily the best way).
# Cache clients in global scope
s3 = boto3.client('s3')
email = EmailService()
def runner(args, email, image):
try:
try:
fake_img = gan.test_endpoint(crop_img)
except Exception as e:
print("ERROR: Processing image with GAN: {}".format(e))
raise e
try:
file_name = 'outgoing/' + image
image_url = s3.put_object(Body=image, Bucket=bucket, Key=file_name)
except Exception as e:
print("ERROR: Uploading image to S3: {}".format(e))
raise e
try:
email.send_email(email, image_url)
except Exception as e:
print("ERROR: Failed to send email: {}".format(e))
raise e
except Exception as e:
print('FATAL ERROR')
print(e)
The question is, why wouldn’t I write better code the first time around?
There’s nothing wrong with writing bad code; but hold yourself accountable for fixing it later.
I found flagging code I wasn’t particularly proud of with #TODO’s helped a lot as a quick and easy way to acknowledge a problem. Then I would make use of IDE extensions like Todo Tree which keeps a running list of code smells and future improvements right in your IDE.
If you are working with other people who are also touching the code base, then It might also be worthwhile setting up a Trello board and jot down the problems there. This helps the rest of your teammates to understand where you might be cutting corners so they are more understanding when you ask for time to clean up code smells at at later date.
Have a Backlog
Overtime in both my professional and personal careers I’ve grown to rely on having a documented backlog of work to work from. During my more junior years, I didn’t fully understand why it was important and how it can be a very helpful tool for managing technical debt.
A backlog exists to help you and your teammates better understand your inflight and future workload.
- Write some dud code? create a task in the backlog to clean it up later
- Running into friction when trying to do something in the codebase? throw a card in the backlog to remind you to automate a process when you have some downtime
- Noticing users complaining about a bug? Backlog!
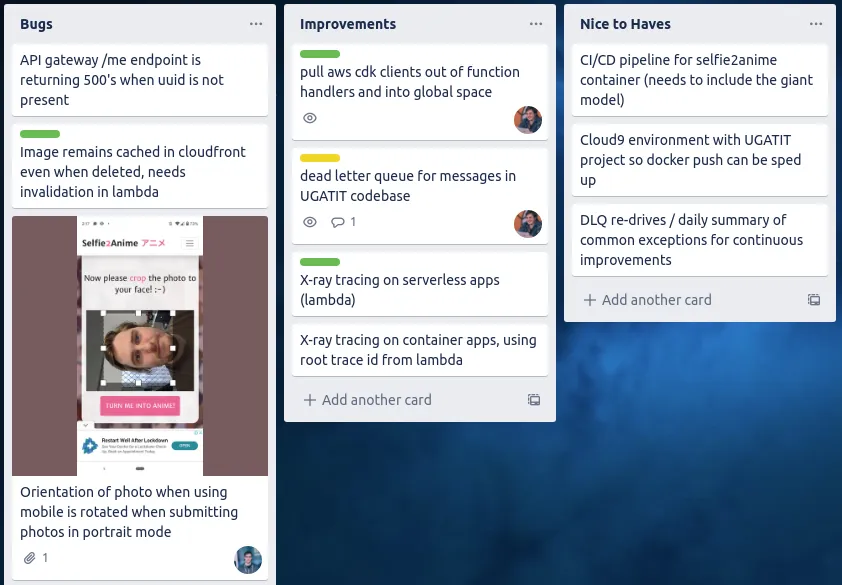
I’ve found that having visibility over tasks and TODO’s in a central place helps keep you accountable, and lets your teammates know what kind of time might need to be invested in the future to retroactively improve the project.
CI/CD is more important then you think (most of the time)
During my day job, I pride myself on the level of work that goes into making sure CI/CD is a first-class citizen. Good CI/CD allows you to move faster and get changes into production more frequently, so it seems like a no-brainer to include it in every project you work on.
There is an argument that trying to setup end to end CI/CD at the start of a project can be a form of procrastination. If this is a very early stage personal project or real experimentation where you are trying to prove something out as quick as possible, then I would argue that an end to end deployment strategy is overkill.
You’ll usually know when it’s time to start setting up a proper deployment pipeline when you are no longer able to make changes regularly, and instead schedule in patches because the process of deploying code has become a hassle.
Automated Builds
I advocate that having an automated build for a new project is always worth setting up, provided it isn’t a job that takes a few days. Having some simple way to confirm builds succeed when pushing to production not only helps you test code more frequently, but it allows other members working on the same codebase to be able to test things themselves without needing your involvement.
A good example of this on Selfie2Anime is our docker container builds. It was taking up to 50 minutes to do a full deploy to production as each container build had to include the 7.6gb selfie2anime model. For the first few weeks, I powered through this inconvenience because I didn’t see it as an important piece of work.
Over time these builds meant I was terrified of making changes because I knew if I messed something up it would be an hour of downtime.
It took me 8 months to implement these automated docker builds. I’m not proud to admit this, and the moment I finally got around to adding them I realized how badly the fear of failed builds was affecting the release cycles. Below is the actual code change I had to make to enable the automated builds, note how few lines it ended up taking verses the months of putting up with slow releases
version: 0.2
phases:
pre_build:
commands:
- mkdir -p checkpoint
- echo Downloading s2a model...
- aws s3 sync s3://devopstar/resources/ugatit/selfie2anime checkpoint/
- echo Logging in to Amazon ECR...
- $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION)
build:
commands:
- echo Building the Docker image...
- docker build -t $IMAGE_REPO_NAME:$CODEBUILD_RESOLVED_SOURCE_VERSION .
- docker tag $IMAGE_REPO_NAME:$CODEBUILD_RESOLVED_SOURCE_VERSION $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$CODEBUILD_RESOLVED_SOURCE_VERSION
post_build:
commands:
- echo Pushing the Docker image...
- docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$CODEBUILD_RESOLVED_SOURCE_VERSION
Another good outcome of setting up this simple automated build was that it gave Rico some context of how the codebase was being built and pushed to production.
A second opinion / Code reviews
Code reviews are another practice that outside of my professional career I didn’t properly see the value in. A large part of why I didn’t see code reviews as important on Selfie2Anime was that I thought full context would be required by the reviewer in order for them to give me meaningful advice.
For example, Rico hadn’t worked on the backend yet so I assumed he wouldn’t have the context to make meaningful criticism.
In reality, his distance from the codebase meant he was able to notice things I had become immune from noticing. A good example of this in action was around the following lines of code that pull messages from a queue and return them for processing
while True:
resp = sqs_client.receive_message(
QueueUrl=queue_url,
AttributeNames=['All'],
MaxNumberOfMessages=10
)
try:
messages.extend(resp['Messages'])
except KeyError:
break
entries = [
{'Id': msg['MessageId'], 'ReceiptHandle': msg['ReceiptHandle']}
for msg in resp['Messages']
]
resp = sqs_client.delete_message_batch(
QueueUrl=queue_url, Entries=entries
)
if len(resp['Successful']) != len(entries):
raise RuntimeError(
"Failed to delete messages: entries={entries} resp={resp}"
)
return messages
Rico asked why there was a while True around this code, as the sqs_client.receive_message function call handled the retrieval of 10 messages for me. The while loop was making the code much more susceptible to error; whereas I looked at it as a way to ensure the application was resilient.

In the end, Rico was right, and having him challenge my perspective means that we now have a much more stable system in place.
Recommendation for solo projects
Talk to your co-workers and friends about your code, chances are they’ll revel at the opportunity to help. I spoke with @jgunnink a lot when I was working on DynamoDB problems (relating to optimally querying information). He made some good comments about why I wasn’t using GSI’s (global secondary indexes). This sparked me to go investigate what they were and how they worked.
This simple conversation helped boost my query performance from >1 minute to under a fraction of a second.
Sharing access
Selfie2Anime is deployed into an AWS account that I own myself, it unfortunately ended up sharing the estate with some other personal projects as well. This has the annoying side-effect of being a little difficult to give my team access to all the resources, while also keeping the data safe and private.
We opted to have myself do all the deployments, which initially wasn’t a problem because I didn’t mind running builds and taking responsibility. However, the outcome of me doing this was that the rest of the team weren’t forced to have exposure to the stack and its complexities. This meant that deploying fell entirely on my shoulders, and there was no incentive for my teammate to learn this for themselves.
Sharing responsibility through equal access, especially on small projects like this one helps alleviate strain on one person
The result was to create a tightly scoped AWS IAM Role that would allow Rico into specific resources within my account.
Summary
Technical debt has many different faces, not all of them can be hidden within code. Some are simply just bad takes by individuals who think they have the best intentions but need some external clarity.
I found working on this project helped me better understand when I was digging a deeper hole instead of solving the root cause of my problems, and moving forward I’m excited to kick off new projects with these lessons learnt in mind.
I would LOVE to hear from anyone who has had to deal with slow growing technical debt, especially on smaller projects. It is difficult to find people wanting to talk about bad experiences; so I encourage you to drop a comment below or hit me up on twitter @nathangloverAUS