Repeatable Data Science - Anaconda Environments

Data Science is becoming more of a hobby for me these days. I specifically adore trying out some of the brilliant work published and distributed in the open source world. There’s very little I can critique when it comes to the actual bread and butter of data science projects, however I do feel as though the average repository and documentation to get projects running yourself could be greatly improved.
This series will be covering a variety of Data Science development techniques and workflows I’ve been trying to perfect in order to more quickly run other peoples code.
Deepcolor Example
This example in no way is meant to be an attack on the creator of this repository (especially seeing as its been a couple years since its release).
kvfrans/deepcolor is a fantastic project that makes use of Conditional generative adversarial networks (cGANs) in order to generate colourised versions of pictures as you draw on them. The project itself by all accounts is very well documented and appears as though you’ll have everything you need in order to run it yourself.
Dependency Hell
For me however something stands out immediately as a problem, all the project dependencies are kind of just thrown at you loosely.
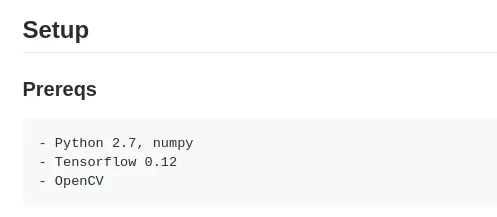
- Prerequisites are defined in the
README.md - Project itself doesn’t have a
requirements.txtfile to lock known working versions - OpenCV as a requirement rather then directing people to opencv-python
Assumed Tooling
If you were to further analyse or even try to run the project you’ll also find that:
- untangle & bottle pip requirements aren’t mentioned at all, but are required.
- Really old version of TensorFlow (by today’s standards)
I like to call this problem assumed tooling as its common to see some requirements left out of project requirements or dependency lists because they already existed on the developers machine. Some notorious offenders are NumPy, Matplotlib & occasionally python.
Bloated and Messy Environments
One of the side effects of having a really diverse set of projects that all include variable dependencies is that developer environments get really messy and hard to work with.
The best example of this is when the default system python is used for projects. You’ll install hundreds of random packages into the system interpreter, then two weeks later run into issues where you have to roll back dependencies to make them work on the next project you try to run.
pyenv and virtualenv do a pretty good job of mitigating this problem however they don’t hold your hand and usually need to be pretty confident your base python is setup properly before you go expanding on it.
Anaconda Environments
The fix for most of the issues outlined above already exists and is used amongst data scientists as a good way of locking in every piece of a projects requirements. Conda is a package manager from Anaconda. It is able to not only manage python dependencies but also binary packages across all operating systems.
Installing Anaconda
Jump over to https://www.anaconda.com/distribution/ and download the most recent version for your operating system.
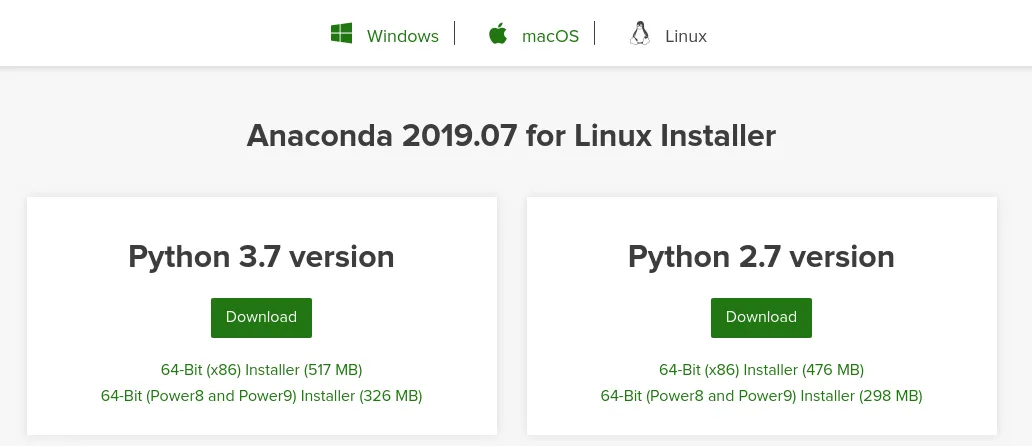
Even if your project is Python 2.7; I’d recommend installing the Python 3.x version. From experience I’ve found that it is still able to setup a Python 2.7 environment for you if defined. Your results might vary.
Once installed on your system confirm you’re able to run the conda command and get an output
conda --version
# conda 4.7.9
Note: Near the end of the installation you’ll be prompted with a question about setting up a default _base_ environment. If you select yes then the following block will be added to your _~/.bashrc_.
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/home/username/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/home/username/anaconda3/etc/profile.d/conda.sh" ]; then
. "/home/username/anaconda3/etc/profile.d/conda.sh"
else
export PATH="/home/username/anaconda3/bin:$PATH"
fi
fi
unset __conda_setup
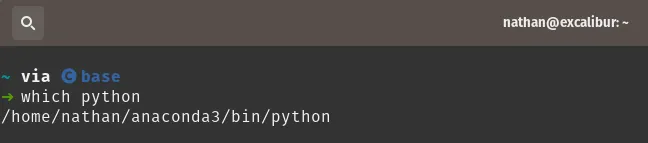
This means that the next time you open up a command line you’ll have your default python setup to use Conda. running which python will prove this.
Environment File
Typically the workflow I will follow when I come across an existing project that doesn’t have conda environments pre-defined (or even lacking pip requirements) is to create a new environment.yml file.
name: project-environment-name # Name of env
channels: # Allow conda-forge (community packages)
- conda-forge
- defaults
dependencies:
- python=2.7 # Python version we'd like
- tensorflow-gpu
# - tensorflow
- numpy
- bottle
- pip
- pip: # Pip specific installs (don't use conda versions)
- untangle==1.1.1 # Define specific version
- opencv-python
I’ve annotated the example above, but there’s a number of ways to define the packages you’d like to bring into a project.
- name - Useful to include a name for the environment in case one isn’t specified at creation.
- channels - Package repositories, default is standard Conda, whereas conda-forge is the community package platform. If you aren’t able to find an up to date package on Conda’s default repository then sometimes it’ll be available on forge.
- dependencies - list of Conda packages to bring in.
- python - The best part about Conda is being able to define a specific python version inside the environment. Conda will fetch the version at creation for use in the project sandbox. Here we have specified python 2.7 specifically.
- tensorflow-gpu - Alternative to just tensorflow for GPU users, Conda will install and setup some of the painful bindings for you enabling easy GPU usage.
- pip - Installing the Conda pip package allows us to specify pip dependencies within the Conda environment file
- Anything placed under
pip:will be installed with pip. Specifying versions is also supported.
- Anything placed under
Create Environment
To create a new environment with your Conda definition, run the following command in the same folder as your environment.yml
conda env create -f environment.yml
# Collecting package metadata (repodata.json): done
# Solving environment: done
# Preparing transaction: done
# Verifying transaction: done
# Executing transaction: done
# To activate this environment, use
# $ conda activate project-environment-name
# To deactivate an active environment, use
# $ conda deactivate
Then run the activate command you were prompted with at the end to activate the environment in your current shell
conda activate project-environment-name
Update Environment
If you need to update a Conda environment after creating it, simply run the following command
conda env update -f environment.yml
Summary
It took me a while to accept that Anaconda was the best way to manage data science project dependencies. I’d come from using virtualenv almost exclusively and didn’t really have much context about how Data scientists were using Python. Once I’d gotten a grip of the workflow however It was pretty clear why conda is so popular.
I hope moving forward its more widely used as it allows less experienced people to jump in and not get burnt out by spending hours getting something working.